
‘n reële mogelijkheid of toekomst muziek?
Door: Michel Boedeltje [
Achtergrond
Bedrijven en organisaties krijgen steeds meer e-mails: logisch want het is makkelijk, je kunt het doen wanneer je wilt en het is (bijna altijd) gratis. Bij nadere bestudering van de inhoud van de e-mails, blijkt een grote overeenkomst met de gesprekken in het call center: 80% van de e-mails gaan over 20% van de onderwerpen. Dat houdt in dat, wanneer je er in slaagt om voor de 20% meest gestelde vragen een algemeen, passend antwoord te maken, je voor 80% van de binnen komende e-mails een kant-en-klaar antwoord hebt.
Dit is ook wat er gebeurt in de zogeheten contact centers. Medewerkers lezen de e-mail en beantwoorden hem middels een voorgedefinieerd antwoord.
Steekwoorden
Er zijn twee manieren waarop het juiste antwoord gezocht kan worden: door de medewerker of door de computer. In de praktijk gaat het echter anders: de computer “leest” de e-mail en schotelt de medewerker op basis van trefwoorden in de e-mail een aantal suggesties voor. De medewerker bekijkt de suggesties en kiest het juiste antwoord. Zolang het aantal suggesties dat de computer voorschotelt klein is (≤5, anders moet de medewerker te veel lezen) en het juiste antwoord er meestal (>80%) bij zit, werkt deze aanpak goed en er zijn verschillende software pakketten te koop die dit zo doen.
Anders wordt het wanneer je meer dan 10 suggesties moet tonen om in slechts de helft van de gevallen er het juiste antwoord uit te kunnen halen: dan wordt het lezen van de suggesties en het alsnog zelf zoeken van het juiste antwoord te tijdrovend en had je het antwoord beter zelf kunnen schrijven.
Uitdaging
Het afstudeeronderzoek van Michel Boedeltje bij Em@ilco in Amersfoort is gestart als een soort wedstrijd: laat zien dat IR (Information Retrieval) technologie in combinatie met taaltechnologie een beter resultaat kan opleveren dan de op steekwoorden gebaseerde methode. Bij de “steekwoorden methode” maakt een mens de keuze om mails met bepaalde woorden aan een bepaald antwoord te koppelen. Staan in de e-mail bijvoorbeeld de woorden “opzeggen” & “internet” dat wordt het standaardantwoord geselecteerd voor mensen die hun internetabonnement willen opzeggen.
Zolang het niet om te gevarieerde mails gaat, werkt dit aardig, maar de resultaten bij Em@ilco lieten zien dat er in de loop van de tijd veel vervuiling optreedt waardoor de resultaten langzaam terug lopen. Mensen zijn blijkbaar niet in staat om voor een verzameling van meer dan 10K (=10.000) e-mails de juiste steekwoorden aan de verschillende standaardantwoorden te koppelen.
Data
De gekozen aanpak was als volgt: verdeel de hele verzameling van 17K (=17.000) e-mail s van de Nationale Postcode Loterij (van iedere e-mail was in theorie het juiste antwoord bekend) in een trainingsdeel (80%) en een testdeel (20%). Laat vervolgens de computer zelf bepalen van welke woorden de aan- en afwezigheid relevant is voor een bepaald antwoord (=klasse). Verander daarbij de test en trainingsgroep een aantal keren zodat er geen toevalligheden optreden en kijk of het eindresultaat beter is. Vermeld moet worden dat de database suboptimaal geclassificeerd was. Van veel e-mails waarvoor het bestaande systeem geen juiste suggestie gaf, was het juiste antwoord op een andere manier aan de afzender gestuurd zonder dit juiste antwoord in de database te noteren. Hierdoor was niet van alle e-mails het juiste antwoord bekend. Ook bleek dat medewerkers vaker dan gedacht verkeerde antwoorden gaven. Tenslotte bleek dat er nogal wat overlap zat in de verschillende categorieën waardoor het, ook voor de medewerkers, niet altijd duidelijk was of een e-mail in de ene of de andere klasse viel.
Aanpak
Deze aanpak klinkt iets simpeler dan het in werkelijkheid is, maar in de basis kwam het hier op neer. Om de rekentijd te verlagen, is het zinvol om de zogeheten stopwoorden (woorden die voor het betekenisonderscheid niet of minder relevant zijn zoals “de”, “het”, “wil”, “mogen”, “wij” etc.) eerst te verwijderen. Vervolgens kan het zinvol zijn de overgebleven woorden te stemmen (fietsen, fiets, fietsje →fiets) om zo de variantie te verminderen. De applicatie moet dan op basis van de resterende woorden bepalen hoe de grenzen tussen de verschillende klassen zo getrokken moeten worden opdat de meeste e-mails in de juiste klasse zouden komen en dus het beste antwoord zouden krijgen.
Resultaat
De resultaten op de 17K e-mails van de Postcode Loterij waren verbazingwekkend goed. Voor ieder aantal suggesties was de kans op succes (d.w.z. het juiste antwoord zit bij de suggesties) meer dan verdubbeld. De kans dat het juiste antwoord erbij zit is bij de nieuwe methode met slechts 2 suggesties al beter dan met 20 suggesties bij de oude methode.
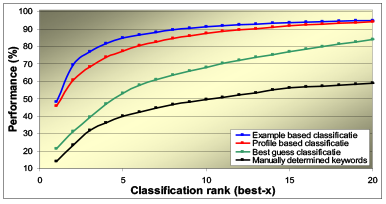
Figuur 1: de resultaten van de verschillende classificatiemethoden vergeleken met de oorspronkelijke, op steekwoorden gebaseerde aanpak. Wanneer we 5 suggesties op het scherm zetten, stijgt de kans van slagen van 40% naar 85%: meer dan een verdubbeling!
De eerste resultaten (slechts gebaseerd op IR-technologie) waren zo goed, dat het toepassen van allerlei taaltechnologie eigenlijk niet zinvol meer leek. Toch hebben we het gedaan en de resultaten werden er alleen maar beter van (hoewel de stijging natuurlijk minder spectaculair was). Zoals uit figuur 2 blijkt is het eerste antwoord in bijna 60% van de gevallen ook het juiste antwoord. Als we dit percentage nog iets kunnen verhogen, dan komt echte self-service (je stuurt een e-mail en het systeem geeft je het (waarschijnlijk) juiste antwoord) binnen bereik.
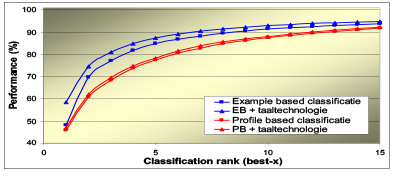
Figuur2: de resultaten van de twee gebruikte IR-methoden met en zonder gebruik van taaltechnologie. Hoewel het verschil afneemt wanneer veel suggesties worden gegeven, is het gebruik van Taaltechnologie zinvol bij volledige self-service waarbij slechts één of twee antwoorden worden gegeven.
Vervolgonderzoek
Hoewel Michel Boedeltje met dit onderzoek zijn studie zeer succesvol heeft afgesloten en nu bezig is de zelfde techniek bij Telecats op gesproken vragen toe te passen, ligt het vervolgonderzoek voor de hand: kun je iets zeggen over de betrouwbaarheid waarmee een antwoord gesuggereerd wordt. Het is waarschijnlijk dat e-mails die qua woordgebruik erg lijken op reeds beoordeelde e-mails, een hoge betrouwbaarheid zullen krijgen. Als dit zo is, wat wordt dan het slagingspercentage als functie van de betrouwbaarheid. Stel dat voor zeer betrouwbare antwoorden het slagingspercentage (de suggestie is juist) 90% is, dan kan overwogen worden om (al dan niet buiten kantoortijden) de e-mailers automatisch antwoord te geven. Dit moet dan uiteraard gepaard gaan met de mededeling dat het antwoord automatisch gegenereerd is en dat men, als het antwoord niet goed is, de vraag nogmaals kan sturen zonder dat men in een soort “loop” terechtkomt.
Conclusie
Het hier gepresenteerde afstudeerwerk laat ‘n aantal zaken duidelijk zien.
- De methode werkt goed, ondanks het feit dat de verzameling waarmee het systeem getraind is ( e-mails-met-antwoord) niet 100% correct is.
- De combinatie van IR en taaltechnologie biedt zeer veel mogelijkheden voor het geheel automatisch beantwoorden van (een deel) van de binnenkomende e-mail
- Het samenwerken van zowel grote als kleine bedrijven met universiteiten kan zeer lonend zijn. Enthousiaste studenten kunnen op deze manier de op de universiteiten aanwezige kennis direct voor bedrijven geschikt en toegankelijk maken.
- Volledig automatische selfservice op een deel van de binnenkomende e-mails onder bepaalde omstandigheden mogelijk is.