
Kunstmatige Intelligentie ofwel AI, is de wetenschap die zich bezig houdt met het door computers nabootsen van "intelligent" gedrag: iets dat wij mensen nu nog als typisch menselijk zien.
Bij Artificial Intelligence (AI) denken we vaak aan (ro)bots: intelligente apparaten die zelfstandig taken uitvoeren.
Regel gebaseerd
En hoewel AI zeker wordt gebruikt bij (ro)bots is het niet hetzelfde. AI kan worden gezien als een verzameling algoritmes[1] die samen ´iets´ slims doen. Bijvoorbeeld: ´als het donker is + er is iemand in de kamer → doe de lamp aan´ en ´als het donker is + er is iemand in de kamer + ik ben op vakantie → bel 112´. Klassieke algoritmes bestaan uit regels die door mensen zijn geschreven, zoals de voorbeelden hierboven. Maar voor veel complexe zaken lukt het mensen niet om de juiste ´Als → Dan´-regels op te stellen.
Machine Learning
Algoritmes gebaseerd op Machine Learning (een vorm van AI) bieden hier de oplossing. Ze zijn in staat te leren van grote hoeveelheden juist geclassificeerde data. Bijvoorbeeld "op deze 100K plaatjes staat een auto & op deze 1M plaatjes staat geen auto" of "deze e-mails zijn ongewenst & deze zijn gewenst".
De software leert van deze voorbeelden en kan hetzelfde trucje succesvol toepassen op nieuwe, ongeziene informatie (nieuw plaatjes of nieuwe e-mails). Op dezelfde manier kan AI een verhoogde kans op autisme detecteren[2], een auto zelfstandig besturen of onze favoriete maandagochtendkoffie prepareren doordat ons gezicht wordt gekoppeld aan onze voorkeur voor koffie op maandagochtend.
Sommige mensen vinden deze gedachte angstaanjagend en zijn bang dat ‘ze’ (de AI-computers) ons leven gaan overnemen. Anderen omarmen deze ontwikkeling en zien deze als een ultieme vorm van gemak. Waarom saaie of repeterende taken uitvoeren als computers dat sneller, beter en goedkoper kunnen? Beide partijen hebben hier (deels) gelijk want alle AI bevindt zich ergens tussen de twee uitersten: zwakke AI en sterke AI.
Zwakke AI
Zwakke AI is gericht op het afhandelen van één specifieke taak. Denk daarbij aan het herkennen van gesproken tekst, het spelen van een spelletje Go of het zelfstandig besturen van een auto.
Sterke AI
Sterke AI is kunstmatige intelligentie die in de buurt komt van onze menselijke intelligentie. Deze vorm van AI is zich bewust van de omgeving en de context waarbinnen ze acteert en kan zich aanpassen aan wisselende situaties.
Patroonherkenning
Een groot deel van de AI die tegenwoordig (2017) zo in het nieuws is, is AI die gebaseerd is op patroonherkenning. Het spelen van het spelletje GO is zo'n voorbeeld of het herkennen van obejecten in plaatjes. Andere voorbeelden zijn het herkennen van patronen in hersenscans (bv om kinder te onderscheiden die wel en die niet een verhoogde kans op de ontwikkeling van autisme vertonen).
Talige AI
Een andere vorm van AI is die zich richt op het nabootsen van de talige en dus menselijke intelligentie. Ht mooiste voorbeeld is IBM's Watson. Watson "leest" documenten en probeert feiten in zinnen aan elkaar te koppelen. In een zin als "Amsterdam, de hoofdstad van Nederland, ligt in het westen van het land en heeft ongeveer 600K inwoners." Hieruit vallen allerlei relaties te distileren zoals:
- Amsterdam -- hoofdstad --> Nederland
- Amsterdam -- aantal inwoners --> 600.000
- Amsterdam -- locatie --> westen van Nederland
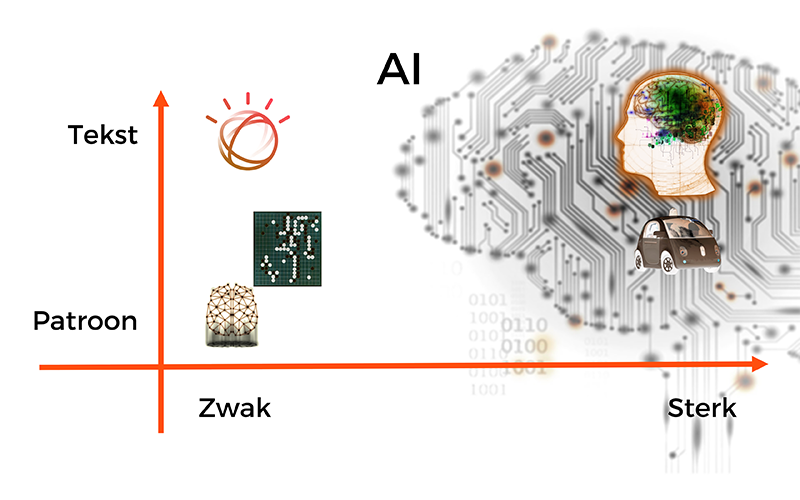 Het speelveld waarop de moderne AI zich begeeft.
Het speelveld waarop de moderne AI zich begeeft.
Zelfstandig rijdende auto's zitten nu nog op zwak-patroon (linksonder)
maar gaan richting sterk en deels talig als we naar niveau-5 gaan.
Maar niet alle AI is gelijk en er zijn veel verschillende technieken in omloop die elk hun specifieke voor en nadelen hebben. Sommige technieken lenen zich voor de ene toepassinge, anderen juist weer voor een andere. In het hieronder staande YouTube filmpje staat een goede en heldere uitleg van de verschillende zaken die bij AI spelen. Filmpje is van dr. Raj Ramesh, de NL-ondertiteling is door mij gemaakt.