
Er zijn verschillende groepen van algoritmes die gebruikt worden om vrije, ongestructureerde taal te “processen”. De oudste groep is die van de Natural Language Processing (NLP) terwijl de twee nieuwere groepen die van de Natural Language Understanding (NLU) en die van Natural Language Generation (NLG) zijn. NLP houdt zich simpel gezegd bezig met het “verwerken” van vrije tekst (via schrift of de ASR van gesproken spraak) in een gestandaardiseerde structuur. NLU daarentegen is een volgende stap en houdt zich bezig met het “interpreteren” van tekst om er betekenis aan te geven. NLG tenslotte is het proces van het genereren van natuurlijk (klinkende) taal.
NLU is een nieuwere verzameling algoritmes die meestal met moderne AI gedaan worden terwijl de klassiek NLP in eerste instantie een wat oudere en meer klassieke set algoritmes betreft.
Geschiedenis NLP
De geschiedenis van de automatische vertaling gaat terug tot de 17de eeuw, toen filosofen als Leibniz en Descartes voorstellen deden voor codes die woorden tussen talen met elkaar in verband zouden brengen. Al deze voorstellen bleven echter theoretisch, en leidde niet tot de ontwikkeling van een echte machine. Het duurde nog tot het midden van de jaren 1930 voordat de eerste octrooien voor het automatisch vertalen werden aangevraagd.
In 1950 publiceerde Alan Turing zijn beroemde artikel "Computing Machinery and Intelligence", waarin hij een voorstel deed voor wat nu de Turing test wordt genoemd als criterium voor intelligentie. Dit criterium hangt af van het vermogen van een computerprogramma om zich in een real-time schriftelijk gesprek met een menselijke rechter voor te doen als een mens, en wel zo goed dat de rechter niet in staat is om - alleen al op basis van de inhoud van het gesprek - op betrouwbare wijze onderscheid te maken tussen het programma en een echt mens.
NLU & NLG
Met de komst van enerzijds snelle computers, het internet en grote hoeveelheden data en anderzijds de snel stijgende (markt)vraag naar snelle en betrouwbare “taalprocessing” algoritmes, begon NLP aan een gestage en steeds snellere opmars. En tegenwoordig zouden we waarschijnlijk niet zonder NLP en eigenlijk ook niet zonder NLU en NLG meer kunnen. Denk aan het automatisch vertalen, het bepalen van de intent van een gesprek, het maken van een samenvatting of geven van persoonlijke informatie in een telefoongesprek.
Bij beiden zien we een verglijkbaar patroon. Het begon ergens in de jaren negentig met vooral op regels gebaseerde systemen maar verschoof met de komst van goede en snelle AI-software al snel richting Kunstmatige Intelligentie.
Voorbeelden
NLP (Natural Language Processing)
Het is wellicht een goed idee om van de drie Natural Language processen een paar voorbeelden te geven. Stel je hebt een telefoongesprek waarin een beller iets wil weten over de vergunningsaanvraag voor een schuurtje. En dat gaat als volgt:
“Goedemorgen, met Pauline. Ik heb drie weken geleden een aanvraag ingediend voor de bouw van een schuur en ik wilde nu wel eens weten hoe het er mee staat.”
De eerste stappen die gedaan moeten worden zijn typische NLP-stappen waarin de ongestructureerde tekst wordt omgezet in een voor een computer begrijpelijk vorm. De NLP-stappen die genomen kunnen worden zijn:
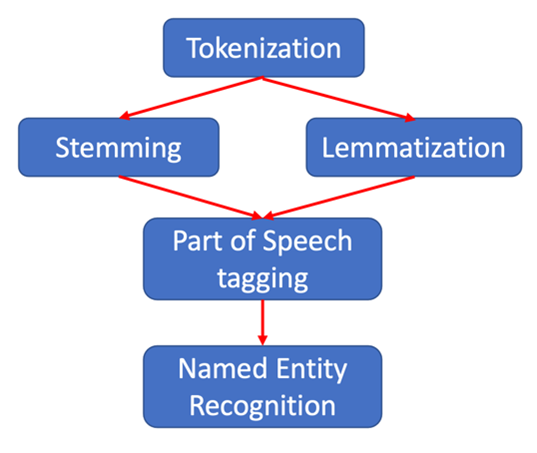 Tokenization: de detectie van ieder afzonderlijk woord. In onze voorbeelzin zijn dit dus 29 tokens.
Tokenization: de detectie van ieder afzonderlijk woord. In onze voorbeelzin zijn dit dus 29 tokens.- Stemming: het herschrijven van een werkwoordsvorm of zelfstandig naamwoord vorm in zijn basis (bv wandelden -> wandelen of huisjes -> huis)
- Lemmatization: het bepalen via een woordenboek (of database) van de betekenis van het woord. Stel je hebt het woord “beter” dan zie je via het woordenboek dat dat komt van “goed”. Het is nu zo dat het of Stemming of Lemmatization is.
- Part of Speech tagging: hiermee bepaal je de klasse van het woord. Is het bijvoorbeeld een werkwoord, een zelfstandig naamwoord of een voorvoegsel?
- Named Entity Recognition: dit is het bepalen of er een entiteit met het woord verbonden is. In onze voorbeeldzin is dit bv Pauline. De entiteit is hier een persoonsnaam.

Nu zijn er uiteraard veel meer tools beschikbaar. Maar we kunnen stellen dat we, afhankelijk van wat we met de inkomende, ongestructureerde tekst willen doen, een aantal NLP-tools op de tekst kunnen loslaten om er op die manier gestructureerde informatie van te maken waarmee de computer vervolgens iets kan doen.
NLU
Stel we hebben twee Engelse zinnen:
- Alice is swimming against the current.
- The current version of the report is in the folder.
In zin 1 is current een zelfstandig naamwoord dat hoort bij swimming terwijl het in zin 2 een adjectief is dat iets zegt over het zelfstandig naamwoord version. Als we al deze onderlinge verbanden goed in kaart brengen, dan kunnen we daarmee iets zeggen over de betekenis van de tekst.
NLG
De andere kant op is NLG. Hiermee maak je een goed klinkende zin in jouw taal, gebaseerd op een set input parameters. Ook hiervoor zijn een hele reeks verschillende algoritmes beschikbaar om een zin bv uitgebreid en beleefd, of juist kort en krachtig te maken. Ook kun je de output (de tekst) geschikt maken voor het hoger opgeleide deel van de samenleving of juist voor hen die de taal (nog) niet helemaal machtig zijn. Hoewel ook NLG begon in het pre-AI tijdperk, zijn de huidige tools allemaal AI-gebaseerd. Ze werken snel, gebruiken relevante data en zijn relatief makkelijk en snel aan te passen.
Toepassingen
Waar worden de verschillende NLP-, NLU- en NLG-algoritme nu gebruikt. Wel, in ongeveer alle moderne toepassingen van bv Call Routing, Q&A en andere telefonieapplicaties van bv Telecats. De eerste vraag die het systeem stelt is vaak om te weten te komen wie er belt. De volgende vraag is dan “waar bel je eigenlijk voor?”. En hier wordt het lastig. Want mensen antwoorden u eenmaal niet met een grammaticaal correcte zin die direct correct te interpreteren is. Stel het antwoord is “ja, ik eh, ik bel eigenlijk om, eh om iets te weten te komen over het, het er nu voor mij voorstaat. Ik bedoel krijg ik die rode stoel nu wel of niet?”
De intent is waarschijnlijk “status update bestelling beller” maar hoe krijg je die intent uit de geuite zin?
Toekomstige ontwikkelingen
Hoewel NLU en NLG beide snelle ontwikkelingen doormaken en er steeds meer tools komen om te begrijpen wat iemand bedoelt, is het nog niet zo dat we klaar zijn. Een belangrijk en deels nog onbekend onderdeel van het begrijpen komt van hoe iets gezegd wordt. Je kunt bv ja zeggen maar het duidelijk maken door de manier waarop je dat zegt, dat je nee bedoelt. Wanneer we ons alleen richten op wat er gezegd wordt, dan krijgen we dus soms een verkeerd antwoord. Deze emotie-detectie is iets waar veel bedrijven mee bezig zijn maar het is behoorlijk lastig omdat de eigenschappen van de spreker hier ook een rol in spelen. Een rustige en beschaafde oudere dame zal nu eenmaal anders spreken dan een opgewonden jongeling. Maar hoe bepaal je wat voor iemand er belt?
Wellicht gaan we hier binnenkort meer over schrijven maar voor nu: veel leesplezier!
Links
https://www.bmc.com/blogs/nlu-vs-nlp-natural-language-understanding-processing/
https://www.youtube.com/watch?v=fLvJ8VdHLA0
https://www.youtube.com/watch?v=1I6bQ12VxV0
https://en.wikipedia.org/wiki/History_of_natural_language_processing
Dit artikel is ook inh et Engels en Frans verschenen op de websites van WebHelp en Telecats