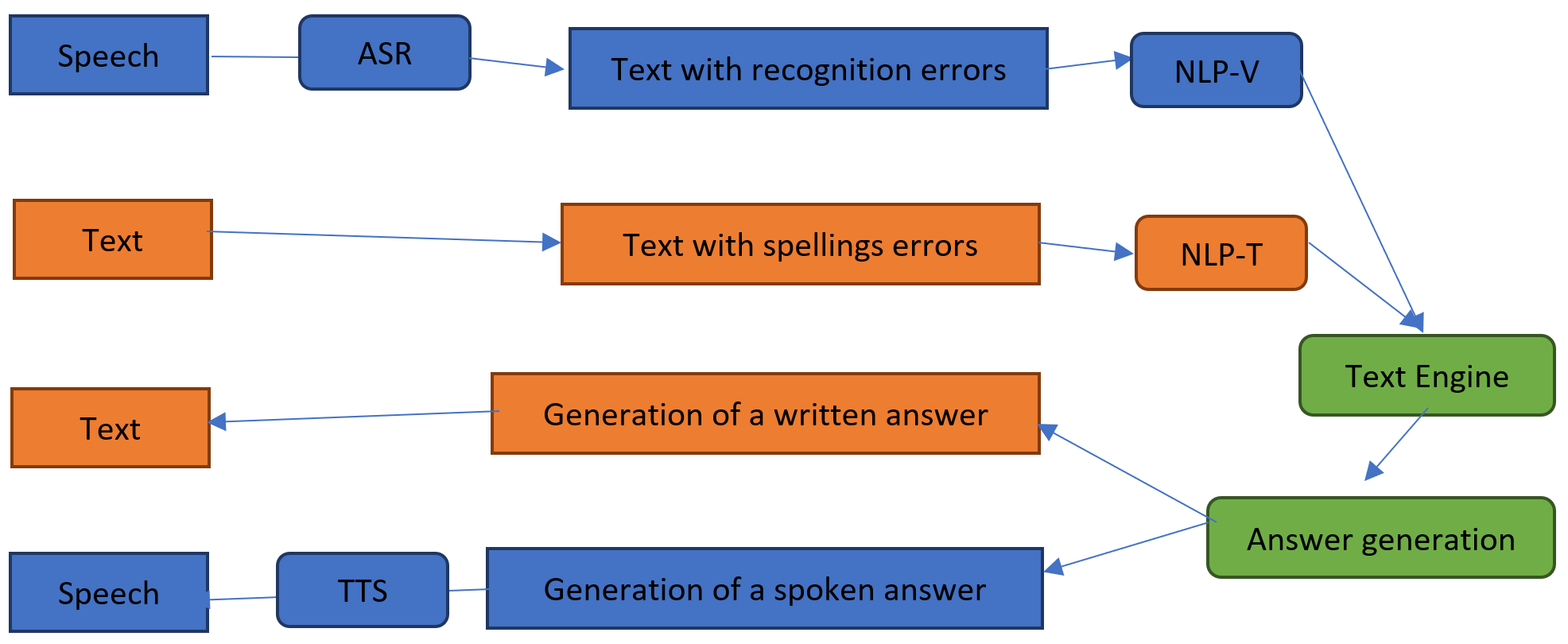
Volgens een studie door gerenommeerde Europese TST-experts worden 21 van de 30 bestudeerde talen (70%) bedreigd met digitale uitroeiing omdat de digitale ondersteuning van deze talen niet of nauwelijks aanwezig is[i]. Dit oordeel is gebaseerd op onderzoek in vier gebieden: automatische vertaling, spraak interactie, tekst analyse en de beschikbaarheid van tekst-corpora. Tekst-corpora zijn noodzakelijke ingrediënten voor de ontwikkeling van de drie genoemde meer complexe Taal- en Spraaktechnologieën. Zulke waardevolle corpora zijn echter dun gezaaid, zelfs voor de meerderheid van de 23 officiële Europese talen. De Eu maakt en bezit grote hoeveelheden meertalige corpora die gebruikt kunnen worden voor de ontwikkeling van taal-gebaseerde applicaties. De EU is dus in de positie om het TST-veld een flinke steun in de rug te geven en dat doet ze dan ook! Wat doen de EU-instituties dan precies? En hoe kan zelfs een eenvoudig verzameling tekst-bestandjes gebruikt worden om taal- en spraaksoftware te ontwikkelen? Wordt de Nederlandse taal bedreigd met digitale uitsterving? Dit zijn een aantal van de vragen die we in het onderstaande document zullen trachten te beantwoorden. Laten we bij het begin beginnen.
Hebben we daadwerkelijk behoefte aan TST-tools voor alle Europese talen?
 Is het werkelijk noodzakelijk dat we tools hebben voor Nederlands, Portugees, Litouws en Sloveens? Kunnen we niet beter allemaal goed Engels leren zodat het probleem is opgelost?
Is het werkelijk noodzakelijk dat we tools hebben voor Nederlands, Portugees, Litouws en Sloveens? Kunnen we niet beter allemaal goed Engels leren zodat het probleem is opgelost?
Dit is min-of-meer de situatie in de VS, een meertalig land met meerdere nationaliteiten waar men besloten heeft allemaal Engels als de nationale taal te gebruiken. Iedere buitenlandse tekst wordt gewoon vertaalt in Engels. Maar, zouden we dat als Europeanen wel willen? Waarom Engels en niet Nederlands, Duits of Frans? Volgens de Eurobarometer[ii], spreekt slechts 38% van de Europeanen voldoende goed Engels als een tweede taal om te kunnen converseren en 58% is in staat om in een willekeurig andere taal te kunnen converseren en je kunt dus stellen dat we nog lang niet het ideaal van een taal bereikt hebben. Bovendien komen in een internationale setting niet-moedertaal sprekers dikwijls als minder ontwikkeld en dommer over dan mensen die hun eigen taal spreken.
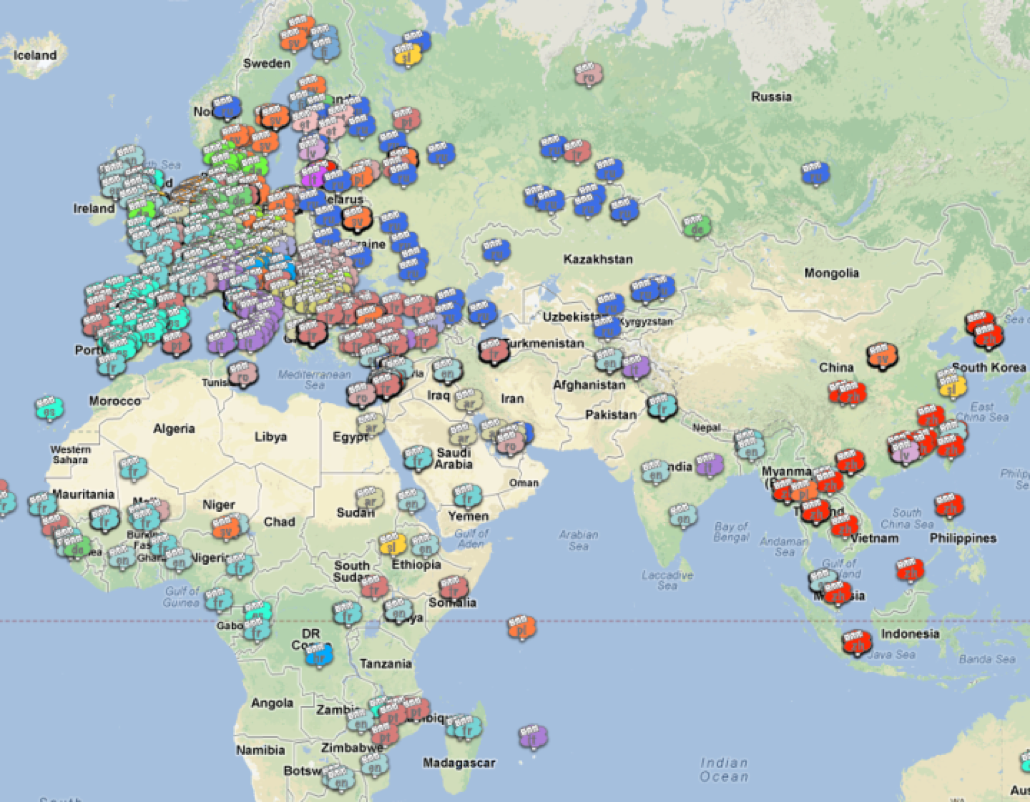
Een ander argument tegen de eenzijdige focus op het Engels is dat we gezien hebben tijdens het jarenlang bestuderen van multinationale media monitoring , dat de verstrekte informatie in het nieuws in de verschillende talencomplementair[iii]is. Alleen wereldomspannende grote gebeurtenissen worden in de verschillende talen gebracht maar de meeste plaatselijke gebeurtenissen worden nooit vertaald en halen niet de internationale pers.
De in dit artikel getoonde kaart van de Europese Media Monitor[iv], toont de plaatsen die genoemd werden in een momentopname van het live news. Elk van de bijna 50 nieuws-talen heeft een eigen kleur gekregen hetgeen duidelijk maakt dat gebeurtenissen in bepaalde gebieden alleen in sommige talen gerapporteerd worden en in andere talen niet. Wanneer we alleen het Engelse nieuws zouden monitoren, dan zouden we de meeste gebeurtenissen en de meeste details domweg missen.
De EU staat op meertaligheid
Ongeveer tien jaar geleden, richtlijn 2003/98/EC[v] van het Europese Parlement en de Raad voor het hergebruik van publieke informatie onderkende dat meertaligheid een van Europa’s basisprincipes is die de culturele en talige diversiteit garandeert.
De wetgevers merkten vervolgens op dat vertaal- en taal-overstijgende informatie toegangstechnologie een potentiële bijdrage kan leveren aan het transparanter, gelijker, verantwoordelijker en democratischer maken van de EU omdat het de burgers toegang geeft tot beleids- en wetgevende voorstellen in alle Europese talen.
En, zou het niet mooi en interessant zijn wanneer we weten wat de (geplande) wetgeving is in de ons omringende landen zegt over genetisch gemodificeerde organisme, over het dragen van een boerka in het publieke domein, en over subsidies voor alternatieve energie? De Richtlijn stelt verder dat taal-overschrijdende toegang een positief effect kan hebben op het weghalen van hindernissen voor concurrentie in de interne markt van de EU. Om al deze redenen plaveide de wetgever alweer negen jaar geleden de weg voor een onbelemmerde toegang voor R&D tot de enorme Europese collectie meertalige teksten.
Hoe kan een eenvoudige document-collectie helpen TST-tools te ontwikkelen?
We hebben dus TST-applicaties in vele talen nodig. Om ze te ontwikkelen hebben we basis resources zoals corpora en woordenboeken nodig en we hebben behoefte aan software componenten zoals morfologische analyse tools, grammaticale ontleders, enz. enz. The Eu heft een groot aantal parallelle corpora; documenten en hun handmatig geproduceerde vertalingen. Parallelle data is bijzonder nuttig omdat het de training mogelijk maakt van statistische vertaalcomputers (niet allen voor Engels, Duits of Frans maar ook voor minder gebruikte talen) . Het kan bovendien gebruikt worden voor het automatisch genereren van woordenboeken. Het staat annotatieprojectie over talen toe zodat het goedkoper wordt om TST-programma’s te maken en te testen. De hierboven genoemde EU-richtlijn van 2003 erkent het nut van EU-gegevens voor het ontwikkelen van TST-hulpmiddelen en het effent de weg voor de vrije en wijdverspreide distributie ervan. In 2006 heeft het eigen Joint Research Centre (JRC) een groot aantal parallelle corpora gemaakt en beschikbaar gesteld; iets dat een significante bijdrage leverde voor het voor de eerste keer ontwikkelen van een automatisch vertaalsysteem voor 462 taal-paren waarvan ook de minder gebruikte taal-paren zoals Portugees-Litouws en Fins-Sloveens deel uitmaakten[vi]. Sindsdien hebben verscheidene in grote mate meertalige EU corpora het licht gezien[vii].
Heeft de EU meer dan ruw tekstmateriaal?

Ja, dat hebben ze! EU organisaties hebben - in een voor computers leesbare vorm – het zeer grote meertalige inter-institutionele terminologie-gegevensbestand IATE[viii], beschikbaar gemaakt. Daarnaast nog verscheidene meertalige thesaurussen en classificaties schema’s (inclusief EuroVoc[ix]en enkele ondersteuningstools en informatie voor vertalers[x]).
In 2011 werd het JRC-Namen[xi]corpus gelanceerd. Een corpus dat bestaat uit automatisch gegenereerde meertalige namenlijsten (zie in het kader de verschillende spellingsvarianten van de naam Bashar Assad). Ook bijbehorende software werd beschikbaar gesteld die gebruikt kan worden voor het verbeteren van het automatisch vertalen van namen. JRC-Namen helpt ook bij het vinden van gelijke namen die verschillend gespeld worden (inclusief de verschillende schrijfwijze in de verschillende lettertype) in dataverzamelingen zoals pers en fotoarchieven. Bovendien helpt het bij het trainen en testen van zogeheten Named Entity herkenningssoftware in verschillende talen. In 2012, werd de tekstcategorisatie tool JRC EuroVoc Indexer (JEX)[xii]gelanceerd. Deze software, die getraind is op 22 talen, claimt de snelheid en consistentie van het werk van bibliothecarissen te verbeteren (zie het EuroVoc screenshot, die de Engelse beschrijving geeft van een Hongaarse tekst). Als softwarecomponent, kan JEX bijdragen aan het vinden van verwante teksten in verschillende talen en van gevallen van cross-linguaal plagiaat.
Deze EU bronnen lossen niet alle problemen op , maar ze brengen ons wel dichter bij het uiteindelijke doel: het makkelijk en in verschillende talen met elkaar kunnen communiceren van mensen en machines! Het grootste voordeel van deze EU-corpora is dat ze een bijna even grote hoeveelheid data bevatten voor de veel en de minder gebruikte talen.
Is het Nederlands een bedreigde taal?
En hoe zit het met het Nederlands? Wordt het bedreigd? Is het voldoende goed toegerust voor de volgende generatie mens-machine interactiesoftware? Volgens de recente META-Net studie, is het Nederlands , samen met het Frans, Duits, Italiaans en Spaans, een van paar Europese talen die “redelijk ondersteund” zijn; alleen het Engels dat een “geode ondersteuning” heeft, doet het beter. Dit is erg goed nieuws voor de Nederlandse taal en een compliment voor de Nederlandse en Vlaamse onderzoekers en hun regeringen die duidelijk meer steun geven dan veel andere landen. Er is echter geen reden tot rust: de weg naar goed werkende tekstanalysesoftware en feilloos werkende mens-machine interactie is lang en moeilijk en de Engelstalige software wordt met een razende snelheid ontwikkeld.
[viii] http://iate.europa.eu/
[xii]c href="http://langtech.jrc.ec.europa.eu/Eurovoc.html">http://langtech.jrc.ec.europa.eu/Eurovoc.html