
A short explanation about Bias in Dutch and English.
Wat is de AI-Bias?
Volgens de Oxford Lexicon[1] wordt een vooroordeel gedefinieerd als "neiging of vooroordeel voor of tegen één persoon of groep, vooral op een manier die als oneerlijk wordt beschouwd" en is het een groter probleem dan vaak wordt gedacht.
Vooringenomenheid bestaat vooral in moderne toepassingen die gebaseerd zijn op kunstmatige intelligentie. Niet elke AI-toepassing, maar vooral die toepassingen die getraind zijn op door mensen gegenereerde data, lopen het risico op een ernstige vooringenomenheid.
Op de website van AI Multiple[2] wordt bias in moderne AI gedefinieerd als "AI Bias is een anomalie in de output van machine learning algoritmen, te wijten aan de bevooroordeelde aannames tijdens het algoritme-ontwikkelingsproces of vooroordelen in de trainingsdata". Of, in gewoon Nederlands: het is de veronderstelling dat de door onze relatief jonge, meestal mannelijke en westers georiënteerde softwareontwikkelaars gegenereerde "gegevens" de norm zijn en dat zij uitwisselbaar zijn met de door "anderen" gegenereerde gegevens.
Als we ons richten op Human Language Technology: als hij mij verstaat, verstaat hij iedereen die Engels spreekt. Maar... we vergeten vaak dat "onze" gegevens, normen en waarden niet zonder meer geldig of waar zijn voor elke Engelssprekende persoon of voor welke andere taal dan ook trouwens. Een algoritme dat met dit soort gegevens is getraind, kan dus heel goed presteren als de gebruikers min of meer tot dezelfde "groep" behoren, maar de prestaties zullen teruglopen als de gebruikers tot een andere groep behoren. Deze verschuiving in de prestaties wordt de bias genoemd.
Bias en data collection
Bij moderne softwareontwikkeling wordt steeds meer gebruik gemaakt van AI-routines waarbij het belangrijkste algoritme wordt getraind op "door mensen gegenereerde" gegevens. Onder "door mensen gegenereerde gegevens" (Human Generated Data - HGD) verstaan we gegevens die door mensen worden geproduceerd en kenmerkend zijn voor die mensen. Denk aan je gezicht, je stem, de manier waarop je loopt of slaapt, of de boeken die je leest.
Vaak begint een project met een goed idee en (een beperkte) hoeveelheid data; data die je vaak uit je eigen omgeving probeert te halen. En daar begint het risico!
De eerste duidelijk herkenbare moderne software bias was bij de herkenning van gezichten. De trainings- en testgroep bestonden uit foto's van jonge, hoog opgeleide (meestal) mannen. Na stevig coderen, trainen en testen werd een behoorlijk goed resultaat bereikt. De software was klaar en kon de markt op!
Maar... het werd duidelijk dat vrouwen minder goed herkend werden dan mannen. Dus werd snel een database met jonge vrouwen toegevoegd en werd het systeem opnieuw getraind. Enige tijd later werd versie twee uitgebracht en nu konden mannen EN vrouwen worden herkend. Maar... het werd duidelijk dat ouderen en/of mensen met andere huidskleuren minder werden herkend. Dus werden nieuwe gegevens toegevoegd en zo ging het een hele tijd door totdat de database een niet-discriminerende, goede weergave was van alle soorten mensen.
Is het vermijdbaar?
In tegenstelling tot veel van mijn collega's ben ik niet echt verbaasd of teleurgesteld over deze resultaten. Je moet immers beginnen met wat beschikbaar is, met mensen van wie je een profiel hebt, een gezicht of hun spraak. En vaak zijn dat mensen die op jou lijken. Het foute eraan, is de time to market. Vooral met door mensen gegenereerde data die je gebruikt voor het trainen van je algoritmes, weet je dat je je data moet vergroten omdat de data een goede en eerlijke representatie moet zijn van de mensen die de software gaan gebruiken. En met de snelle toename van AI-gebaseerde software in ons dagelijks leven, betekent dit vaak iedereen. Dus als je eenmaal hebt bewezen dat het principe werkt, moet je doorgaan met het verzamelen van nieuwe gegevens van mensen die anders zijn dan jij en dan opnieuw beginnen met de training.
Automatische Spraakherkenning
Bestaat er een vooroordeel bij spraakherkenning? Helaas, ja! Het is niet anders dan bij andere op AI gebaseerde toepassingen die gebruik maken van HGD. Bij ASR en andere spraak-gebaseerde projecten geldt de "bias wet". We trainen de herkenner op hoe en wat WIJ zeggen, en met WIJ bedoelen we: onze woorden, onze stemtoon en natuurlijk onze uitspraak. Zodra Spraakherkenning de laboratoria verliet, begon het zijn marktintroductie als een gebruikersspecifieke toepassing waarmee wij bepaalde groepen semi-automatisch konden helpen om iets gemakkelijker, sneller, en/of goedkoper te krijgen.
Maar Spraakherkenning werd beter en beter, het werd populair, en het werd gebruikt door een groeiende groep andere mensen. En naarmate de gebruikersgroep groeide, kwamen de oorspronkelijke aannames (je spreekt zoals ik, je zegt dit of dat zoals ik dat doe) steeds meer in het gedrang. Terwijl we vijf à tien jaar geleden nog konden zeggen dat we "correct gesproken Engels" van "native English people" konden herkennen. Hoewel dit nog steeds waar is, blijkt het steeds minder bruikbaar te zijn. Het Engels is de Lingua Franca van onze tijd en het wordt gesproken door een enorme verscheidenheid van mensen die het Engels niet als moedertaal hebben. Van de ongeveer 1,5 miljard mensen die Engels spreken, gebruiken er minder dan 400 miljoen het als eerste taal. Dat betekent dat meer dan 1 miljard mensen het als een secundaire taal spreken met hun eigen, soms typische uitspraak .
Bovendien is spraakherkenning niet iets wat je maakt en voor de komende 50 jaar laat zoals het is. Talen veranderen altijd, nieuwe generaties spreken bestaande woorden anders uit, de taal zelf verandert onder invloed van naburige talen, en door immigranten en tweedetaalsprekers: het gebruik van de taal door groepen die de taal voordien niet spraken.
Luister maar eens naar een interview met een niet-moedertaalspreker van het Engels of naar een uitzending uit de jaren dertig. Je kunt het meestal wel volgen, maar voor onze oren klinkt het vreemd. Om de spraakherkenning bij te houden en nieuwe, jonge, oudere, zieke of dialectsprekende Engelsen te kunnen herkennen, en te kunnen leveren wat ze vragen, moet de Automatische Spraakherkenning voortdurend worden bijgewerkt.
U moet gesprekken verzamelen, uw modules hertrainen en naar buiten brengen. Dan, niet stoppen maar doorgaan. En als u klaar bent, bent u dan klaar? Niet helemaal, want afgezien van de langzaam verdwijnende vooringenomenheid, moeten we ons richten op het volgende grote niet: "begrijpen wat er bedoeld wordt". Maar dat komt een andere keer aan de orde.
What is the AI-Bias?
According to the Oxford Lexicon[1] a Bias is defined as "inclination or prejudice for or against one person or group, especially in a way considered to be unfair" and is a bigger problem than often thought.
Bias exists especially in modern applications that are based on Artificial Intelligence. Not every AI-application but especially those that are trained on human-generated data, are at risk of a severe bias.
At the website of AI Multiple[2], bias in modern AI is defined as “AI Bias is an anomaly in the output of machine learning algorithms, due to the prejudiced assumptions made during the algorithm development process or prejudices in the training data”. Or, in plain English: it is the assumption that our relatively young, mostly male and Western-oriented software developers generated “data” is the norm and that it is interchangeable with the data generated by "others".
If we focus on Human Language Technology: if he understands me, he understands everyone who speaks English. But... we often forget that "our" data, norms and values are not simply valid or true for every English-speaking person or for any other language by the way. So, an algorithm trained with this kind of data can perform very well if the users are more or less from the same “group” but the performance will drop down if the users are from a different group. This shift in performance is called the Bias.
Bias and data collection
Modern software development uses more and more AI-based routines where the main algorithm is trained on “human generated” data. Under “Human Generated Data” (HGD) we consider data that is produced by humans and are characteristic for those humans. Think about your face, your voice, the way you walk or sleep, or the books you read.
Often a project starts with a good idea and (a limited) amount of data; data that you often try to get from your own environment. And there the risk starts!
The first clearly recognisable modern software bias was with the recognition of faces. The training and testing group consisted of pictures of young, high educated (mostly) men. After severe coding, training and testing a pretty good result was achieved. The software was ready and it could go to market!
But... it became clear that women were less well recognised than men. So, a database with young women was quickly added and the system was re-trained. Sometime later, version two was released and now men AND women could be recognised. But... it became clear that elderly people and/or people with other skin colours were less recognised. So, new data were added and it went on for a long time until the database was a non-discriminating, good representation of all kind of humans.
Is it avoidable?
Unlike many of my colleagues, I’m not really surprised or disappointed by these results. After all, you have to start with what’s available, with people of whom you have a profile, a face or their speech. And often these are people who are similar to you. The wrong thing about it, is the time to market. Especially with human generated data you use for training of your algorithms, you know that you have to enlarge your data because the data must be a good and honest representation of the people who will use the software. And with the fast increase of AI-based software in our daily life, this often means everyone. So, once you have proved that the principle works, you must continue to collect new data from people who are different from you and then start the training again.
Automatic Speech Recognition
Is there a bias with speech recognition? Unfortunately, yes! It is not different to other AI-based application that use HGD. With ASR and other speech-based projects “bias law” applies. We train the recogniser on how and what WE say, and by WE we mean: our words, our tone of voice and of course our pronunciation. Once Speech Recognition left the laboratories, it started its market introduction as a user-specific application with which we could semi-automatically help certain groups to get something easier, faster, and/or cheaper.
But Speech Recognition got better and better, it became popular, and it was used by a growing group of other people. And as the user group expanded, the original assumptions (you speak like me, you say this or that as I do) were increasingly compromised. Whereas five to ten years ago we could still say that we could recognise “correctly spoken English” of “native English people”. Although still true, this turns out to be less and less useful. English is the Lingua Franca of our time and it is spoken by a huge variety of people who do not have English as their mother tongue. Of the approximately 1.5 billion people who speak English, less than 400 million use it as a first language. That means over 1 billion speak it as a secondary language with their own, sometimes typical pronunciation .
Moreover, Speech Recognition is not something you make and leave it as it is for the next 50 years. Languages always change, new generations pronounce existing words differently, the language itself changes under the influence of neighbouring languages, and through immigrants and second-language speakers: the use of the language by groups who didn’t speak that language before.
Just listen to an interview with a non-native English speaker or a broadcast from the 1930s. You can usually follow it, but for our ears it sounds strange. In order to keep up with speech recognition and to be able to recognise new, young, older, sick, or dialect-speaking English people, and to deliver what they ask for, the Automatic Speech Recogniser must be updated continuously.
You need to gather conversations, retrain your modules and bring it out. Then, don’t stop but continue. And once done, are you ready? Not quite, because apart from the slowly disappearing bias, we need to focus on the next big stap: “understanding what is meant”. But that will be discussed another time.
Links
- https://research.aimultiple.com/ai-bias/
- https://www.speechmatics.com/resources/articles-and-news/how-to-tackle-ai-bias
- https://www.agconnect.nl/artikel/helft-gebruikers-klaagt-dat-spraaktechnologie-stemmen-niet-verstaat
- https://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf
- https://www.youtube.com/watch?v=TWWsW1w-BVo
- https://medium.com/thoughts-and-reflections/racial-bias-and-gender-bias-examples-in-ai-systems-7211e4c166a1
Images
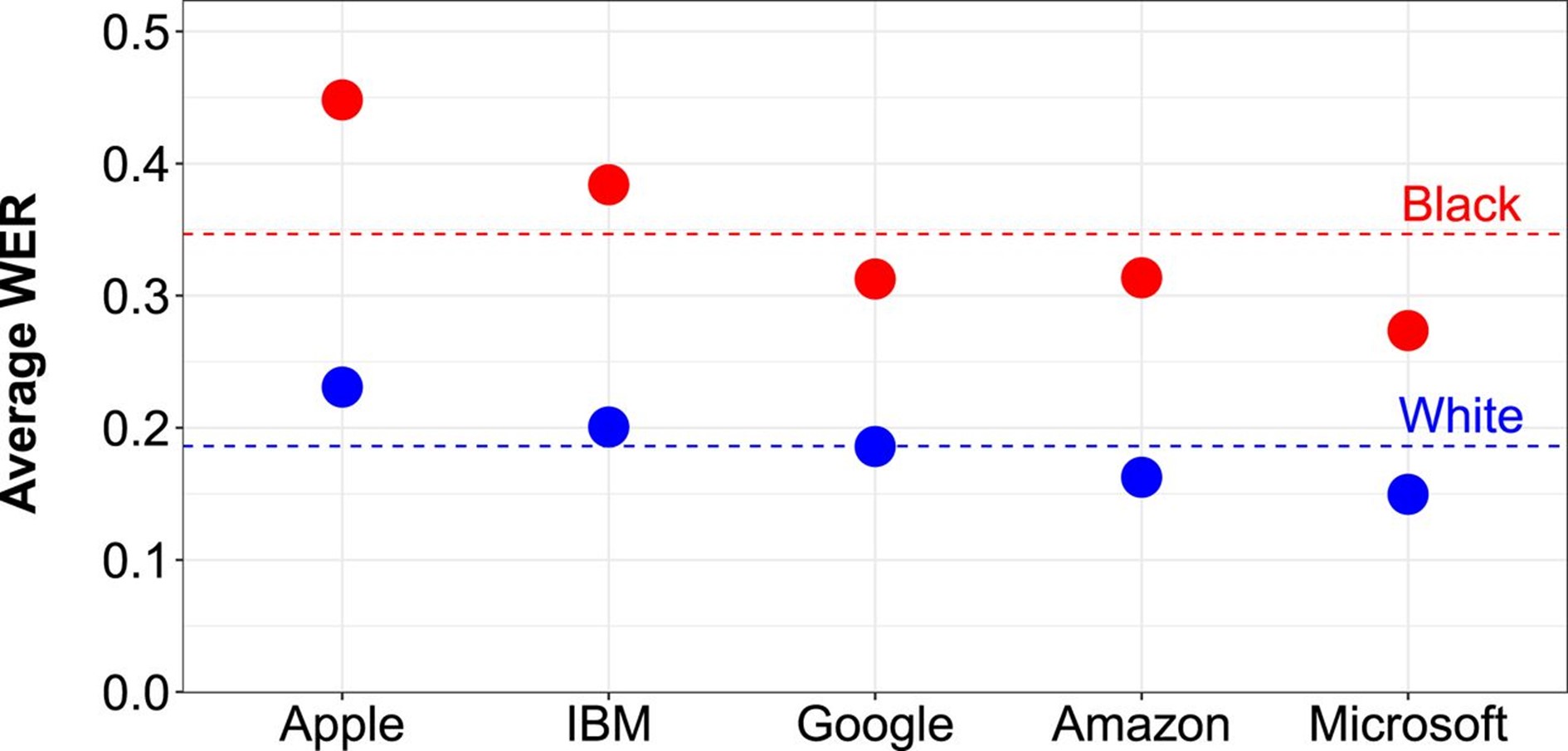
Figure 1: The average WER across ASR services is 0.35 for audio snippets of black speakers, as opposed to 0.19 for snippets of white speakers. The maximum SE among the 10 WER values displayed (across black and white speakers and across ASR services) is 0.005. For each ASR service, the average WER is calculated across a matched sample of 2,141 black and 2,141 white audio snippets, totalling 19.8 h of interviewee audio. Nearest-neighbour matching between speaker race was performed based on the speaker’s age, gender, and audio snippet duration.

Figure 2: The results of an AI system. Guided by the risk assessments, judges in courtrooms throughout the United States would generate conclusions on the future of defendants and convicts, determining everything from bail amounts to sentences. The software estimates how likely a defendant is to re-offend based on his or her response to 137 survey questions. It was discovered that the COMPAS algorithm was able to predict the particular tendency of a convicted criminal to reoffend. However, when the algorithm was wrong in its predicting, the results was displayed differently for black and white offenders.
Figure 3: Amazon’s biased recruiting tool. With the dream of automating the recruiting process, Amazon started an AI project in 2014. Their project was solely based on reviewing job applicants’ resumes and rating applicants by using AI-powered algorithms so that recruiters don’t spend time on manual resume screen tasks. However, by 2015, Amazon realized that their new AI recruiting system was not rating candidates fairly and it showed bias against women.

Figure 4: Kriti Sharma; a leading global expert in AI and its impact on society and the future. She tells in an inspiring TED Talk about AI bias, here personal experience and what she did to avoid being taken seriously as a woman in the AI world.
[1] Oxford Lexicon: https://www.lexico.com/definition/bias
[2] AI Multiple https://research.aimultiple.com/ai-bias/