
 Artikel door Miciel Rohlof over "AI in het juridisch systeem".
Artikel door Miciel Rohlof over "AI in het juridisch systeem".
Interview is gedeeltelijk gebaseerd op een telefonisch interview met Arjan van Hessen (sept 2017)
De toepassing van AI, ofwel artificiële intelligentie, in de advocatuur en rechtsspraak leek tot voor kort nog toekomstmuziek. De ontwikkelingen gaan echter razendsnel en het zal niet lang meer duren vóór we de eerste robot-adviezen, of zelfs door computers gegenereerde rechtspraak zullen zien. Buiten de ethische kwesties rijzen er ook praktische vragen op, want op welke gebieden kun je AI het beste inzetten en is het ook daadwerkelijk beter dan een menselijke variant? Mr. ging in gesprek met enkele ‘early adaptors’…
Sinds juni 2017 heeft ROSS Intelligence een heuse R&D-afdeling op de universiteitscampus van Toronto in Canada, de stad waar deze succesvolle AI-onderneming is ontstaan. ROSS is een ‘robot-advocaat’: gebruikers stellen een vraag per telefoon of laptop en ROSS geeft een zo relevant mogelijk antwoord. Daarnaast houdt ROSS bij welke ontwikkelingen effect kunnen hebben op lopende zaken en wordt het systeem steeds intelligenter naarmate er meer advocaten gebruik van maken.
AI-technologie zoals ROSS, levert in de juristerij - en in veel andere sectoren, zoals de zorg - potentieel een enorme efficiëntieslag en kostenbesparing op. Toch leken advocatuur en rechtspraak tot nu toe terughoudend en keek men de welbekende kat uit de boom. Misschien door te weinig inzicht in de verschillende systemen, te weinig inhouse IT-expertise, of zelfs angst voor concurrentie voor deze ‘robot-juristen’. Dat het werk van juristen de komende jaren echter flink kan veranderen door de opkomst van AI, lijken steeds meer mensen nu te beseffen. Juridische dienstverleners die dankbaar gebruik maken van AI in plaats van het te verwerpen, zijn in opkomst en het zegt veel dat een grote uitgever als Wolters Kluwer alle rechtspraak momenteel digitaal doorzoekbaar maakt.
Volgens dr. Arjan van Hessen, onderzoeker bij het Enschedese bedrijf Telecats en aan de universiteiten van Twente en Utrecht en specialist op het gebied van Taal- en Spraaktechnologie en Kunstmatige Intelligentie, is de mogelijke impact van AI op de advocatuur en rechtspraak enorm. “Als het goed werkt, zijn er straks minder advocaten en rechters nodig om de zelfde hoeveelheid werk te doen. Dat besef lijkt langzaam door te dringen, en lang niet iedereen is er uiteraard blij mee”, aldus Van Hessen. “Ik ga regelmatig naar bijeenkomsten op het gebied van legal tech en waar het twee jaar terug nog een handvol kantoren waren, schuiven inmiddels alle grote kantoren aan. Bedrijfsjuristen vragen hun advocaat naar de mogelijkheden en grote Angelsaksische kantoren investeren flink in technologie. De noodzaak om mee te doen is inmiddels doorgedrongen.”
Maar wat verstaan we precies onder AI? Van Hessen onderscheidt verschillende typen kunstmatige intelligentie: algemene AI, waarbij een soort alwetende computer wordt gebouwd die veel verschillende soorten taken kan vervullen, en dedicated-AI, gericht op het uitvoeren van één taak: het scannen van grote hoeveelheden gegevens, besturen van een auto of winnen van een go-wedstrijd.
Daarnaast kun je AI ruwweg onderverdelen in cognitieve systemen zoals Watson en op patroon gebaseerde systemen zoals Deep Mind van Google. Cognitieve AI systemen zijn gebaseerd op menselijke communicatie zoals bv taal. Ze kunnen documenten “lezen” doordat ze een taal (vaak Engels) “kennen”. Ze kunnen bv het onderscheid maken tussen “Hans draagt Piet” en “Hans wordt door Piet gedragen”. Hiermee kunnen ze informatie halen uit geschreven bronnen (bv uit de duizenden medische publicaties die er per dag verschijnen). De meer op patronen gerichte AI werkt iets anders. Hierbij worden bv plaatjes aangeboden (van katten of hersenscans) en wordt er bij gezegd dit is een poesje en dit niet, of dit kind ontwikkelde een autisme storing en dit kind niet. Als voldoenden data wordt gebruikt kan de computer “leren” welke patronen wel en welke niet tot een bepaalde uitslag leiden. Van Hessen: “Met name die laatste categorie wordt steeds vaker toegepast. De politie herkent bijvoorbeeld patronen van inbraak en surveilleert vervolgens vaker in wijken met een hoger risicoprofiel. De belastingdienst gebruikt AI om te voorspellen welke aangiftes volgend jaar frauduleus zullen zijn – met een vrij hoge slagingskans. En bij hypotheekaanvragen gaat het gros van de eerste schifting al via AI, met een overschot aan financieel specialisten en een tekort aan mensen die de beslissing van een computer kunnen uitleggen tot gevolg.”
Voor de FIOD werkt van Hessen aan innovatie op het gebied van toegepaste spraakherkenning, waarbij opgenomen verhoren met behulp van spraakherkenning getranscribeerd worden. De op deze wijze verkregen teksten (met fouten want spraakherkenning is niet perfect) worden gecombineerd met andere geschreven bronnen zoals een proces verbaal of een bestaand dossier. Computers kunnen dan gelijksoortige onderwerpen in de verschillende documenten aan elkaar koppelen waardoor een veel beter overzicht verkregen wordt. Echter: op dit moment mogen niet zomaar alle oude, reeds afgesloten zaken gebruikt worden. Het koppelen van nieuwe informatie met bv een 5-jaar oude zaak is daarom niet zonder meer mogelijk. Maar wellicht gaat dat veranderen, want dat mocht eerst ook niet met DNA-technologie.
We zien nu dat computers steeds beter in staat zijn om uit (enorme) grote hoeveelheden data informatie te distilleren. En deze informatie kan vervolgens gebruikt worden om, al dan niet zelfstandig, beslissingen te nemen. Of we dit nu leuk vinden of niet, het is een ontwikkeling die we niet kunnen negeren. Het is daarom beter gewoon te accepteren dat het er komt en ons te richten op de beste manier om er mee om te gaan. Hoe ga je het gebruiken en wat zijn de ethische dilemma’s die gebruik van AI oproepen? Hoe voorkom je een situatie waarin geen mens meer kan uitleggen waarom een bepaalde beslissing werd genomen (“The computer says NO”)? Hoe meer dit soort AI een rol zal gaan spelen op het gebied van rechtspraak, zorg of financiën, hoe belangrijker de transparantie (verklaren van de beslissing) zal worden. Daarom zou het goed zijn als er op de universiteiten veel meer aandacht voor dit onderwerp zou komen, want duiding van kunstmatige intelligentie wordt steeds belangrijker, ook in de juridische wereld.”
En daar wringt de schoen nog een beetje: het lijkt erop dat de juridische faculteiten het onderwerp vooralsnog amper omarmd hebben, terwijl de behoefte aan ‘legal tech’ specialisten alleen maar zal toenemen. Een gemiste kans, denkt Ivar Timmer, onderzoeker en hoofddocent bij de master Legal Management van de Hogeschool van Amsterdam (HvA). “IT gaat de rechtspraktijk veranderen en daar ligt een belangrijke taak voor het juridisch onderwijs. Ik heb de indruk dat universiteiten moeite hebben om hier goed op in te spelen, terwijl hogescholen er volop mee bezig zijn. Een belangrijk deel van het ‘legal tech’-werk sluit bijzonder goed aan bij het profiel van de hbo-jurist. Om legal tech-applicaties in de dagelijkse praktijk te bemensen heb je hybride professionals nodig; juridisch onderlegd personeel, met goede kennis en vaardigheden op het gebied van IT. In deze toenemende arbeidsmarktbehoefte proberen wij te voorzien door mensen op te leiden op het snijvlak van recht, legal tech en procesmanagement.”
In het curriculum van de HvA wordt nu al aandacht besteed aan deze onderwerpen, maar dit programma wordt geïntensiveerd en zal de komende jaren worden ingevoerd. Recent is een uitgebreid traject gestart om de juridische docenten verder te scholen in legal tech en kunstmatige intelligentie. Timmer verwacht dat uiteindelijk steeds meer hbo-juristen hun weg zullen vinden richting advocatuur en bedrijfsleven, zeker als de AI-technologie meer gemeengoed wordt. Timmer: “Het gaat bij de keuze tussen een universitair of hbo-jurist niet primair om het kostenplaatje; het gaat erom het juiste profiel bij de juiste functie te zetten. Nu technologie snel een grotere rol gaat spelen ontstaat een noodzaak tot meer functiedifferentiatie in de juridische wereld. Daarvoor is een diversiteit aan professionals nodig. Een klassiek geschoolde universitaire jurist heeft simpelweg niet de beste opleiding om geautomatiseerde systemen en AI-resultaten te analyseren. Dat gaan de meer hybride opgeleide hbo-juridische professionals doen.”
Over naar de praktijk. Hoe zette advocatenkantoren en juridisch dienstverleners AI momenteel in om efficiënter – en misschien ook winstgevender – te werken? Bij advocatenkantoor HVGLaw lanceert men eind oktober een eigen tool gebaseerd op AI, genaamd ‘Genius’. Daarmee worden standaardcontracten gegenereerd op basis van vragenlijsten die cliënten invullen – tot zover nog niet revolutionair – maar de output ervan wordt steeds slimmer naarmate het gebruik toeneemt en de tool bedenkt zelfstandig waar de gebruiker eventueel behoefte aan heeft. Kunstmatige intelligentie dus, ingezet als service voor de cliënt. Managing partner Johan Westerhof: “Voorafgaand aan dit idee hebben we een rondje langs de velden gedaan: waar hebben onze cliënten behoefte aan? We zien AI vooral als een toevoeging op de bestaande adviesrol, maar wel één met veel potentie. In het notariaat zijn ook veel toepassingen van AI denkbaar.”
De keuze om ‘Genius’ in huis te bouwen terwijl er toch al redelijk wat bestaande aanbieders zijn was volgens Westerhof eenvoudig. “Wat wij graag wilden, was er nog niet.” Naast de investeringen in ‘Genius’ en andere AI-gerelateerde software investeert HVGLaw daarom ook in personeel dat meer kan dan het puur juridische. “We hebben net een jurist aangenomen die ook kan programmeren. Verder organiseren we interne ‘legal hackatons’ om onze eigen, meer IT-onderlegde mensen te enthousiasmeren bij te dragen aan innovatie binnen ons kantoor. In de nabije toekomst zie ik hier veel meer data-juristen en programmeurs rondlopen.”
Volgens Jelle van Veenen, legal service designer bij Kennedy van der Laan, kijken kantoren nog te veel naar de eigen interne processen en denkt men dat het inkopen van AI voldoende is om processen te verbeteren. Terwijl bij een focus op de cliëntbehoefte relatief eenvoudige oplossingen vaak al tot grote verbeteringen kunnen leiden. Van Veenen: “Er ligt heel veel winst in beter begrip van de cliëntbehoeftes en daar op een andere manier producten tegenover zetten. AI-technologie kan daarbij helpen: het zet mensen aan om anders na te denken over het werk dat ze doen. Ons kantoor is al jaren actief op het gebied van legal tech, maar cliënten stellen steeds vaker ook proactief de vragen: wat doen wij om zaken slimmer aan te pakken? Begrip van de materie is daarom een basisbehoefte, zeker als de rechterlijke macht ook steeds meer kunstmatige intelligentie gaat gebruiken. Iedereen wil mee in de trend en advocatenkantoren kunnen vanuit hun adviesrol de leiding nemen.”
Volgens Van Veenen loopt men in de VS voorop: daar is intelligente software die uitspraken van rechters kan voorspellen en verbanden kan leggen tussen vergelijkbare zaken, om vervolgens ook een voorspellende waarde te geven over de slagingskans van een rechtszaak.
“Ook in Nederland gaan we zien dat AI steeds meer inzicht gaat verschaffen in juridische kennis en juridische werk”, aldus Van Veenen. “De academische budgetten voor onderzoek naar AI lijken momenteel te krimpen, maar innovatie gaat de komende jaren ook veel meer uit het werkveld komen. “Producten uit de VS zijn hier vaak niet zomaar in te zetten, onder andere door de taalbarrière en verschillen in de markt. Daardoor zie je wel steeds meer dat men in Europa zelf producten gaat ontwikkelen.”
Het probleem dat belangrijke AI-software in het Engels is en daarom niet uit de voeten kan met Nederlandse input, was voor directeur Luc van Daele van juridisch dienstverlener Legadex één van de aanleidingen om zelf met AI aan de slag te gaan. Legadex maakt gebruik van diverse soorten AI-software maar werkt bij de ontwikkeling van nieuwe toepassingen vooral intensief samen met softwarehuis ZyLAB. Dat systeem wordt gebruikt in situaties waarin sprake is van veel ongestructureerde informatie of wanneer informatie uit verschillende bronnen moet komen. Van Daele: “Slimme AI-toepassingen kun je programmeren om zoveel mogelijk informatie uit bijvoorbeeld een dataset te halen en daar conclusies aan te verbinden. Eerder dit jaar hebben we dat als de ‘Review Robot’in de markt gezet en bijvoorbeeld gebruikt bij de overdracht van een omvangrijke hypotheekportefeuille geweest, waarvoor data van een langere periode vanuit verschillende bronnen moest worden samengebracht, teneinde de portefeuille te verkopen. Rond zo’n transactie is het van belang de portefeuille compleet en in heldere samenhang te kunnen presenteren. Zo’n toepassing klinkt voor de hand liggend, maar is in de uitvoering toch vrij revolutionair: je traint de algoritmen dusdanig dat ze patronen herkennen en gaandeweg slimmer worden. Zonder toepassing van AI is dat onbegonnen werk of onbetaalbaar.”
Legadex gebruikt AI onder meer bij M&A en due diligence processen, maar ook voor zgn. ‘corporate housekeeping’ en contractmanagement. Van Daele: “Met name wanneer grote hoeveelheden moeten worden verwerkt en geanalyseerd. Met AI kun je niet alleen de dataverwerking flink versnellen maar, nog interessanter, je maakt je informatie zeer transparant en kunt onderlinge verbanden zien.” Cliënten zijn er volgens Van Daele erg blij mee. Maar werkt het ook beter dan de menselijke variant? “Er gaat veel voorbereidingstijd in zitten om alles goed in de systemen te krijgen, maar als het eenmaal operabel is, is de foutmarge van zo’n systeem een stuk lager dan bij de mens, al maak ik me met zo’n constatering vast niet geliefd”, aldus Van Daele. “Een verschil zit ook in het feit dat een systeem herleidbaar kan aangeven wanneer het iets mist of welke gegevens ontbreken. Bij mensen krijg je zo’n rapportage niet en het menselijk oog mist veel wat door de machine wel gemakkelijk en met een hoge mate van zekerheid wordt opgepikt. De traditionele juristerij realiseert zich vaak nog maar heel beperkt wat daarmee nu al mogelijk is.”
Het zal nog wel even duren voordat software op basis van kunstmatige intelligentie op grote schaal menselijke advocaten zal vervangen; in eerste instantie zullen ze de advocaten ondersteunen. Toch zullen dienstverleners erin mee moeten, denkt Arjan van Hessen, want het is niet ondenkbaar dat er op korte termijn voor particulieren een AI-achtige toepassingen zal worden gelanceerd – waarmee dienstverleners gedeeltelijk buiten spel worden gezet. “Denk aan uitgevers die alle rechtspraak geprocessed hebben en daarmee een adviesgenerator lanceren: in 80% van de vergelijkbare gevallen oordeelde de rechter negatief dus wellicht is het niet verstandig om een proces te beginnen. Niemand zal een oordeel volledig bij een computer willen leggen, maar wanneer AI de komende jaren gemeengoed wordt binnen de rechtspraak zal ook de vraag gesteld worden of een eerste oordeel niet net zo goed van een computer kan komen. Die discussie wordt ook gevoerd in de medische wereld, want als het oordeel van een systeem voor 99% overeenkomt met het gemiddelde van 5 medisch specialisten, is het dan niet veel efficiënter om Watson die dure specialisten te laten vervangen? Naarmate het verschil in kosten hoger en het verschil in kwaliteit lager wordt, moeten we sterk in onze schoenen staan om de mens in control te houden. Zeker omdat de gefinancierde rechtshulp ook al jaren onder druk staat.”
Daar komt het andere grote gevaar van kunstmatige intelligentie nog bij: algoritmen worden getraind op basis van informatie die mensen in een systeem zetten, en dat kan verkeerd uitpakken. Van Hessen: “Google is weleens verweten racistisch te zijn, want als je op ‘witte teenager’ of ‘zwarte teenager’ zoekt krijg je bij de eerste groep meer ideale schoonzonen en bij de tweede groep meer criminelen in de gevangenis. Het systeem werd getraind met door mensen getagde foto’s op Internet, en is niet een oordeel van Google , maar zo werd het in eerste instantie wel geïnterpreteerd. Dat ging verder toen eerder dit jaar een Amerikaanse rechtbank AI gebruikte om te bepalen of iemand met vervroegd verlof mocht of niet. Het systeem werd met een grote hoeveelheid verschillende parameters getraind (gedroegen ze zich goed of vervielen ze weer in de oude fout, ras/kleur, leeftijd, gender, info over de ouders en grootouders, etc.). De voorspellende waarde, op basis van de gebruikte gegevens was hoog, maar de software ging toch de fout in omdat de link “zwart -> armoede -> armoede in eerdere generaties -> kans op recidive hoog” werd vervangen door “zwart -> kans op recidive hoog”. Een typisch geval van het doorelkaar halen van causaliteit en correlatie en maatschappelijk onacceptabel. Er zal dus altijd een menselijke check nodig zijn en we moeten leren begrijpen hoe een algoritme werkt, voordat we meer aan de computers over gaan laten.”
Michiel Rohlof
Om verder te lezen:
- De voorzitter van de Raad voor de rechtspraak sprak deze speech uit tijdens de Dag van de Rechtspraak op 28 september 2017
- Dringend gezocht: rechters met kennis van cybercriminaliteit
- In 2030 zullen computers rechtspreken
- De zwarte doos gaat rechtspreken
- Silicon Valley ziet de mens als een algoritme
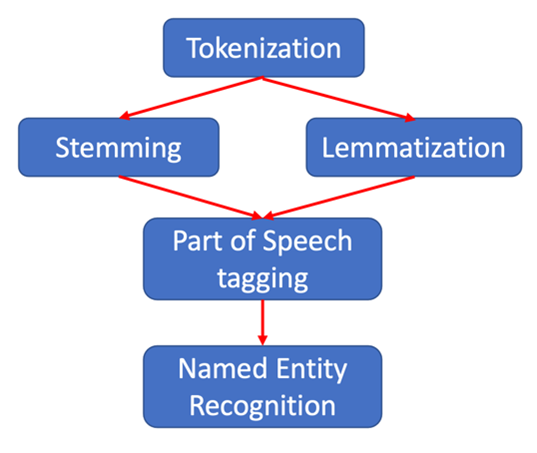 Tokenization: de detectie van ieder afzonderlijk woord. In onze voorbeelzin zijn dit dus 29 tokens.
Tokenization: de detectie van ieder afzonderlijk woord. In onze voorbeelzin zijn dit dus 29 tokens.