
Luisteren
“Niets is zo lastig als het voorspellen van de toekomst” is een veel gehoorde kreet. Toch is het iets dat wij mensen eigenlijk de hele dag doen. Wanneer iemand tot ons spreekt en wij aandachtig luisteren, dan zetten we de binnenkomende klanken om in de meest waarschijnlijke reeks opeenvolgende woorden. Hierbij proberen we steeds te voorspellen welke woorden waarschijnlijk gesproken zullen gaan worden, gegeven het onderwerp van het gesprek, de spreker en de net gehoorde woorden.
 Fig. 1: De klankreeks “isdevorstingevallen” kan leiden tot “is de vorst ingevallen” maar ook tot “is de vorstin gevallen”
Fig. 1: De klankreeks “isdevorstingevallen” kan leiden tot “is de vorst ingevallen” maar ook tot “is de vorstin gevallen”
Hoe beter wij kunnen voorspellen wat er gezegd gaat worden, hoe langzamer het gesprek lijkt te gaan en hoe makkelijker het is om het gesprek goed te volgen. Je weet als het ware halverwege de zin al wat er gaat volgen.
Andere taal
Iedereen kent wel het verschijnsel dat je veel meer moeite moet doen om een gesprek te volgen wanneer het in een andere taal gesproken wordt en/of wanneer het onderwerp geheel nieuw voor je is. Bij veel internationale vergaderingen die (bijna) altijd in het Engels zijn, zie je mensen die wat meer moeite hebben het gesprek te volgen, zo gaan zitten dat ze het gezicht van de spreker goed kunnen zien. De visuele informatie (openen en sluiten van de mond, de bewegingen van de lippen etc.) geeft een klein beetje extra informatie over wat er gezegd wordt en dat helpt bij het volgen van het gesprek. Ook goede (visuele) informatie van bv een PowerPointpresentatie helpt de toehoorders doordat de te bespreken onderwerpen op het scherm zichtbaar gemaakt worden.
Naarmate je beter in het onderwerp thuis bent en de gesproken taal beter kent, kun je als luisteraar beter voorspellen wat de spreker waarschijnlijk gaat zeggen en lijkt de spraak langzamer te gaan. Het kost je dan minder moeite om zo’n gesprek te volgen. En wanneer je op een verjaardagsfeestje naast die vervelende “one-topic” neef zit dan heb je aan twee woorden al genoeg om de komende 5 minuten te kunnen voorspellen.
Kortom: het goed volgen van een gesprek is deels niets anders dan het goed voorspellen van wat er gezegd gaat worden.
Simultaan vertalen
Wanneer we luisteren naar spraak dan zijn we dus steeds aan het voorspellen. En hoe meer woorden we horen hoe zekerder we zijn van wat er nog gezegd gaat worden. Maar zeker in het begin van een nieuwe zin, zijn er nog heel veel mogelijk woorden die met een hoge waarschijnlijkheid kunnen volgen.
 Fig. 2: voorbeeldzin waarin het “cruciale” werkwoord pas helemaal op het einde komt. Voor een simultane vertaling in bv het Engels moet je eigenlijk al direct weten welk van de vier opties gekozen gaat worden. In dit voorbeeld is gestapeld het meest waarschijnlijk doordat haardhout dat bezorgd wordt (in Nederland) meestal al gezaagd, gehakt of gespleten is. Op het Franse platteland echter waar je het hout bij een naburige boer hebt gekocht, krijg je in de regel stammen van 4 meter geleverd en is gezaagd een veel waarschijnlijker kandidaat.
Fig. 2: voorbeeldzin waarin het “cruciale” werkwoord pas helemaal op het einde komt. Voor een simultane vertaling in bv het Engels moet je eigenlijk al direct weten welk van de vier opties gekozen gaat worden. In dit voorbeeld is gestapeld het meest waarschijnlijk doordat haardhout dat bezorgd wordt (in Nederland) meestal al gezaagd, gehakt of gespleten is. Op het Franse platteland echter waar je het hout bij een naburige boer hebt gekocht, krijg je in de regel stammen van 4 meter geleverd en is gezaagd een veel waarschijnlijker kandidaat.
Maar dit wordt lastig als je simultaan moet vertalen omdat de woordvolgorde per taal kan verschillen. Talen als het Duits, Nederlands en Chinees zijn berucht om het helemaal op het einde plaatsen van het belangrijkste werkwoord zoals in bovenstaande voorbeeld en in fig. 4 hieronder. In het Engels plaats je dit werkwoord juist in het begin.
Maar wanneer je simultaan moet vertalen en dus geen tijd hebt om te wachten tot de gehele zin gesproken is, dan moet je gaan gokken welk mogelijk werkwoord gezegd zal gaan worden en dat dus uitspreken, voordat het in de brontaal daadwerkelijk wordt uitgesproken.
Automatisch vertalen
Met de komst van “Deep Learning” is de kwaliteit van automatische vertalingen enorm vooruitgegaan. Het is (nog) niet feilloos en mist soms de finesse maar meestal is het resultaat, als de invoertekst niet te ingewikkeld of ambigue is, goed te lezen en te begrijpen. Voorbeelden van op Deep Learning gebaseerde vertaal software zijn DeepL en Google Translate
Deze automatisch vertaalsoftware is "opeenvolgend" en gebruikt echter de gehele (geschreven) zinnen en heeft dus geen last van het moeten voorspellen van wat er gaat komen: dat is bekend op het moment dat de vertaling begint.
|
Nederland |
Engels |
|
Ik heb het haardhout dat gisteren |
I have the firewood that yesterday |
|
Ik heb het haardhout dat gisteren gebracht |
I have brought the firewood that yesterday |
|
Ik heb het haardhout dat gisteren gebracht werd |
I have the firewood that was brought yesterday |
|
Ik heb het haardhout dat gisteren gebracht werd, gestapeld |
I have stacked the firewood that was brought yesterday |
Fig. 3: Simulatie van simultaan vertalen. Van een zin worden steeds meer woorden gebruikt voor de vertaling. De vertaling is hier pas ok, wanneer alle woorden bekend zijn. Dat komt hier doordat het essentiële werkwoord (gestapeld) in het Nederlands pas helemaal op het einde wordt gegeven.
Vertalen van spraak
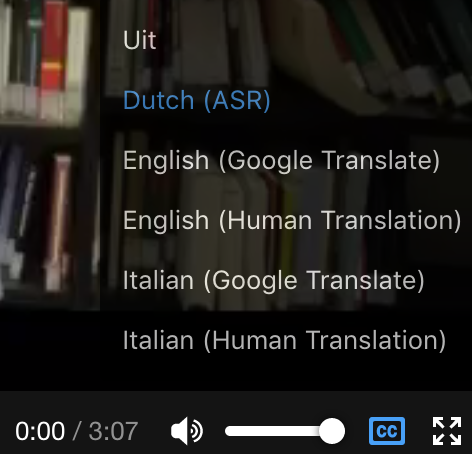 Fig. 4: Voorbeeld van de verschillende semi-automatisch gegenereerde ondertitels van een Nederlands gesproken interview. In een Europees Oral History (OH) project zijn we bezig met een Transcripty Chain waarmee we automatisch de gesproken spraak (Duits, Italiaan, Engels en Nederlands) kunnen herkennen van de talloze OH-interviews waarvan geen transcriptie bestaat. Doel is de vindbaarheid en doorzoekbaarheid van die interviews te vergroten.
Fig. 4: Voorbeeld van de verschillende semi-automatisch gegenereerde ondertitels van een Nederlands gesproken interview. In een Europees Oral History (OH) project zijn we bezig met een Transcripty Chain waarmee we automatisch de gesproken spraak (Duits, Italiaan, Engels en Nederlands) kunnen herkennen van de talloze OH-interviews waarvan geen transcriptie bestaat. Doel is de vindbaarheid en doorzoekbaarheid van die interviews te vergroten.
Maar om de interviews te ontsluiten voor een internationaal publiek volstaat een transcriptie in een (kleinere) gesproken taal dikwijls niet omdat maar weinig mensen al die verschillende talen verstaan. Om de (her-)bruikbaarheid van die interviews verder te vergroten, worden ze, nadat de spraak herkend is, automatisch vertaald in het Engels.
De spraakherkenningsresultaten zijn behoorlijk goed maar het resultaat is echter een reeks woorden zonder begin (hoofdletter) en eind (punt, vraagteken). Kijk maar eens naar de automatische ondertiteling van een willekeurig YouTube filmpje. De woorden worden getoond wanneer ze uitgesproken worden, maar er ontstaan geen zinnen.
Toen we de spraakherkenningsresultaten door de automatische vertaler haalden, kregen we veelal onzin. Het automatisch vertalen werkte pas goed nadat we de ASR-resultaten (zonder ze te verbeteren) handmatig in een soort van zinnen hadden onderverdeeld.
Vertalen door pro’s
Het zal duidelijk zijn dat simultaan vertalen van bijvoorbeeld VN-vergaderingen een zeer lastige en vermoeiende klus is. Als een hoogwaardigheidsbekleder spreekt, moeten de tolken tegelijkertijd luisteren, geestelijk vertalen en spreken in een andere taal met meestal slechts een paar woorden vertraging. Het is zo'n moeilijke taak dat VN-tolken meestal in teamverband werken en in ploegendiensten van slechts 10 tot 30 minuten vertalen. Automatisch simultaan vertalen biedt hier, mits het goed werkt, een uitkomst.
AI voorspelt wat je gaat zeggen
Maar de nieuwe AI-aangedreven tool van Baidu Research, STACL genaamd, kan wellicht hulp bieden met een automatische vertaling die slechts een paar woorden achterblijft op het origineel. Dit wordt gedaan door te voorspellen wat iemand over een paar seconden gaat zeggen zegt Liang Huang, hoofdwetenschapper van Baidu's Silicon Valley AI Lab. "Het is een techniek die gelijk is aan wat menselijke tolken de hele tijd gebruiken en die van cruciaal belang is voor het gebruik van automatische vertalen in de echte wereld.”
STACL kan dat probleem omzeilen door het werkwoord te voorspellen, gebaseerd op alle zinnen die het in het verleden heeft gezien. Voor hun huidige paper hebben de Baidu-onderzoekers STACL getraind op nieuwsberichten, waar hetzelfde verhaal in het Engels en het Chinees verscheen.
 Fig. 5: Voorbeeld van de verschillende plek waar het essentiële woord in de zin (ontmoeten) in het Engels en het Chinees staat.
Fig. 5: Voorbeeld van de verschillende plek waar het essentiële woord in de zin (ontmoeten) in het Engels en het Chinees staat.
De AI leert als het ware welk werkwoord in een bepaalde zin waarschijnlijk gaat komen, en kan dat werkwoord alvast gebruiken in de vertaling. Op dit moment is het systeem getraind met zinnen die te maken hebben met internationale politiek, maar er is geen technische belemmering om dit ook voor berichten uit de medische of sportwereld te doen.
Emotie
Een bijkomend probleem van het simultaan vertalen is dat de keuze van bepaalde (werk)woorden een emotionele lading kunnen hebben. Gebruik je het ene dan is dat neutraal terwijl het andere een positieve of juist negatieve connotatie heeft. Huang geeft een voorbeeld van een Chinese zin, die het meest direct vertaald zou worden als: "Xi Jinping Franse president bezoekt drukt waardering uit". STACL, echter, raadt vanaf het begin van de zin dat het bezoek waarschijnlijk goed gaat, en vertaalt de zin als: "Xi Jinping drukt waardering uit voor het bezoek van de Franse president".
Voor het bestellen van een biertje op een terras, maakt zo’n subtiliteit waarschijnlijk niet veel uit, maar bij een internationale topontmoeting kan de wel uitgesproken, maar niet vertaalde positieve connotatie tot misverstanden. En natuurlijk, kan ook een menselijke tolk deze fout maken, maar die kan zich verontschuldigen en de gemaakte fout herstellen: STACL kan dat voorlopig niet.
Vertraging
Het systeem is echter wel aanpasbaar en je kunt besluiten de latentie (de wachttijd voor je met het vertalen begint) te vergroten. Besluit je bv om pas met vertalen te beginnen als je al vijf woorden (ipv drie woorden) hebt gehoord, dan stijgt de kans op een juiste vertaling aanzienlijk.
STACL werkt op dit moment voor het Chinees – Amerikaans en Amerikaans – Chinees, maar er is geen beperking aan wat het aankan, anders dan de beschikbaarheid van voldoende trainingsdata. STACL zal gedemonstreerd worden op de Baidu Wereldconferentie op 1 november, waar het zal zorgen voor een live simultaanvertaling van de toespraken.
Hardware
 Fig. 6: Big Blue die de toenmalige wereldkampioen schaken (Gasparov) in 1997 versloeg. Nu vereist STACL nog een zware computer, maar uiteindelijk zal het op je smartphone gaan draaien. Dat klinkt als Science Fiction, maar de huidige smartphone is hoewel niet krachtiger, wel een stuk slimmer dan de enorme Deep Blue computer die in 1997 wereldkampioen schaken werd!
Fig. 6: Big Blue die de toenmalige wereldkampioen schaken (Gasparov) in 1997 versloeg. Nu vereist STACL nog een zware computer, maar uiteindelijk zal het op je smartphone gaan draaien. Dat klinkt als Science Fiction, maar de huidige smartphone is hoewel niet krachtiger, wel een stuk slimmer dan de enorme Deep Blue computer die in 1997 wereldkampioen schaken werd!
Verantwoording
Dit stuk is geschreven na het lezen van een interessant stukje in de nieuwsbrief De Bicker en het bijbehorende artikel in IEEE Spectrum van Eliza Strickland en bedoeld als achtergrondinformatie voor de lezing tijdens het 2018 DRONGO-festival.
