
Een jargonvrije uitleg van hoe AI en grote taalmodellen werken.
 Toen ChatGPT in de herfst van 2022 werd geïntroduceerd, ging er een schok door de technologie-industrie en de rest van de wereld. Machine learning-onderzoekers experimenteerden toen al een paar jaar met grote taalmodellen (LLM's), maar het grote publiek had niet goed opgelet en besefte niet hoe krachtig ze waren geworden.
Toen ChatGPT in de herfst van 2022 werd geïntroduceerd, ging er een schok door de technologie-industrie en de rest van de wereld. Machine learning-onderzoekers experimenteerden toen al een paar jaar met grote taalmodellen (LLM's), maar het grote publiek had niet goed opgelet en besefte niet hoe krachtig ze waren geworden.
Tegenwoordig heeft bijna iedereen van LLM's gehoord en tientallen miljoenen mensen hebben ze uitgeprobeerd, maar slechts weinig mensen begrijpen echt hoe ze werken.
Als je iets over dit onderwerp weet, heb je waarschijnlijk gehoord dat LLM's worden getraind om "het volgende woord te voorspellen" en dat ze enorme hoeveelheden tekst nodig hebben om dit te doen. Maar daar houdt de uitleg meestal mee op. De details over hoe ze het volgende woord voorspellen worden vaak behandeld als een “diep mysterie”.
Een van de redenen hiervoor is de ongebruikelijke manier waarop deze systemen zijn ontwikkeld. Conventionele software wordt gemaakt door menselijke programmeurs, die computers expliciete, stapsgewijze instructies geven. ChatGPT daarentegen is gebouwd op een neuraal netwerk dat is getraind met behulp van miljarden woorden uit gewone taal. Als gevolg hiervan begrijpt (bijna) niemand op aarde volledig hoe LLM's in elkaar zitten. Onderzoekers werken aan een beter begrip, maar dit is een langdurend proces dat jaren - misschien wel decennia - in beslag zal nemen.
Desondanks begrijpen experts wel veel van de werking van deze systemen. Het doel van dit artikel is om veel van deze kennis toegankelijker te maken voor een breed publiek. We zullen proberen uit te leggen wat er bekend is over de innerlijke werking van deze modellen zonder terug te vallen op technisch jargon of geavanceerde wiskunde.
We beginnen met het uitleggen van woordvectoren, de verrassende manier waarop taalmodellen taal weergeven en erover redeneren. Daarna duiken we dieper in de "transformator", de basisbouwsteen voor systemen als ChatGPT. Tot slot leggen we uit hoe deze modellen worden getraind en onderzoeken we waarom voor goede prestaties zulke fenomenaal grote hoeveelheden gegevens nodig zijn.
Word vectors
Om te begrijpen hoe taalmodellen werken, moet je eerst begrijpen hoe ze woorden representeren. Mensen representeren woorden met een reeks letters, zoals K-A-T voor "kat". Taalmodellen gebruiken een lange lijst getallen die een "woordvector" wordt genoemd. Dit is bijvoorbeeld een manier om kat als een vector voor te stellen:
[0.0074, 0.0030, -0.0105, 0.0742, 0.0765, -0.0011, 0.0265, 0.0106, 0.0191, 0.0038, -0.0468, -0.0212, 0.0091, 0.0030, -0.0563, -0.0396, -0.0998, -0.0796, ..., 0.0002]
(De volledige vector is 300 getallen lang-om alles te zien, klik hier en klik dan op "Show the raw vector.")
Analogie
Waarom zo'n barokke notatie gebruiken? Washington DC ligt op 38,9 graden noord en 77 graden west. We kunnen dit weergeven met een vectornotatie:
- Washington, DC, ligt op [38,9, 77].
- New York ligt op [40,7, 74]
- Londen ligt op [51,5, 0,1].
- Paris ligt op [48.9, -2.4].
Dit is handig om te redeneren over ruimtelijke relaties. Je kunt zien dat New York dicht bij Washington DC ligt, omdat 38,9 dicht bij 40,7 ligt en 77 dicht bij 74 ligt. Op dezelfde manier ligt Parijs dicht bij Londen. Maar Parijs ligt ver van Washington DC.
Taalmodellen gebruiken een vergelijkbare benadering: Elke woordvector vertegenwoordigt een punt in een denkbeeldige "woordruimte" en woorden met meer overeenkomstige betekenissen worden dichter bij elkaar geplaatst (technisch gezien werken LLM's op fragmenten van woorden die tokens worden genoemd, maar we zullen dit implementatiedetail negeren om dit artikel beheersbaar lang te houden).
Bijvoorbeeld, de woorden die het dichtst bij kat staan in de vectorruimte zijn hond, kitten en huisdier. Een belangrijk voordeel van het representeren van woorden met vectoren van echte getallen (in tegenstelling tot een reeks letters, zoals K-A-T) is dat getallen bewerkingen mogelijk maken die letters niet kunnen.
Woorden zijn te complex om in slechts twee dimensies weer te geven, dus gebruiken taalmodellen vectorruimten met honderden of zelfs duizenden dimensies. De menselijke geest kan zich een ruimte met zoveel dimensies niet voorstellen, maar computers zijn prima in staat om erover te redeneren en bruikbare resultaten te produceren.
Onderzoekers experimenteren al tientallen jaren met woordvectoren, maar het concept kwam pas echt van de grond toen Google in 2013 het word2vec-project aankondigde. Google analyseerde miljoenen documenten uit Google News om uit te zoeken welke woorden vaak in vergelijkbare zinnen voorkomen. Na verloop van tijd leerde een neuraal netwerk, getraind om te voorspellen welke woorden samen voorkomen met andere woorden, om woorden die op elkaar lijken (zoals hond en kat) dicht bij elkaar te plaatsen in de vectorruimte.
Google's woordvectoren hadden nog een intrigerende eigenschap: Je kon over woorden "redeneren" met behulp van vectorrekenkunde. Onderzoekers van Google namen bijvoorbeeld de vector voor 'grootste', trokken 'groot' ervan af en voegden 'klein' toe. Het woord dat het dichtst in de buurt kwam van de resulterende vector was "kleinste".
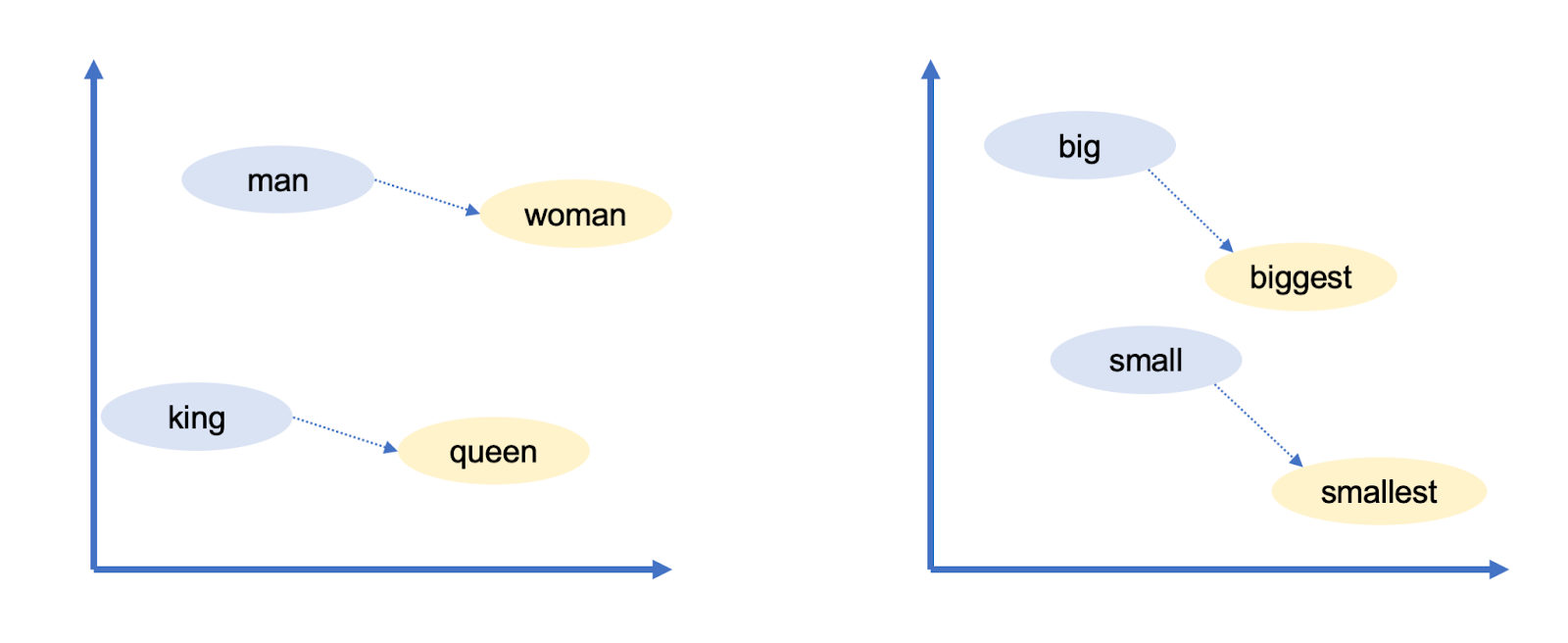 Fig. 2
Fig. 2
Je kunt vectorrekenen gebruiken om analogieën te trekken! In dit geval is groot gelijk aan grootst zoals klein gelijk is aan kleinst. Google's woordvectoren hebben nog veel meer relaties vastgelegd:
- Zwitsers staan voor Zwitserland zoals Cambodjanen voor Cambodja (nationaliteiten)
- Parijs is voor Frankrijk zoals Berlijn voor Duitsland (hoofdsteden)
- Onethisch is voor ethisch als onmogelijk is voor mogelijk (tegenstellingen)
- Muis is voor muizen zoals dollar is voor dollars (meervouden)
- Man is voor vrouw als koning is voor koningin (geslachtsrollen)
Omdat deze vectoren zijn opgebouwd uit de manier waarop mensen woorden gebruiken, weerspiegelen ze uiteindelijk veel van de vooroordelen die aanwezig zijn in de menselijke taal. In sommige woordvectormodellen levert "dokter min man plus vrouw" bijvoorbeeld "verpleegster" op. Het verminderen van dit soort vertekeningen is een gebied van actief onderzoek.
Niettemin zijn woordvectoren een nuttige bouwsteen voor taalmodellen omdat ze subtiele maar belangrijke informatie coderen over de relaties tussen woorden. Als een taalmodel iets leert over een kat (bijvoorbeeld dat hij soms naar de dierenarts gaat), dan geldt dat waarschijnlijk ook voor een kitten of een hond. Als een model iets leert over de relatie tussen Parijs en Frankrijk (ze delen bijvoorbeeld een taal), dan is de kans groot dat hetzelfde geldt voor Berlijn en Duitsland en voor Rome en Italië.
Woordbetekenis hangt af van context
Een eenvoudig woordvectorschema als dit legt een belangrijk feit over natuurlijke taal niet vast: Woorden hebben vaak meerdere betekenissen.
Het woord "bank" kan bijvoorbeeld verwijzen naar een financiële instelling of naar een meubel waar je op kunt gaan zitten of liggen. Of kijk eens naar de volgende zinnen:
- Jan pakt een tijdschrift.
- Susan werkt voor een tijdschrift.
De betekenissen van tijdschrift in deze zinnen zijn verwant, maar verschillen subtiel. Jan pakt een fysiek tijdschrift, terwijl Susan werkt voor een organisatie die fysieke tijdschriften uitgeeft.
Als een woord twee niet-verwante betekenissen heeft, zoals bank, noemen taalkundigen het homoniemen. Als een woord twee nauw verwante betekenissen heeft, zoals tijdschrift, spreken taalkundigen van polysemie.
LLM's zoals ChatGPT kunnen hetzelfde woord met verschillende vectoren weergeven, afhankelijk van de context waarin dat woord voorkomt. Er is een vector voor bank (financiële instelling) en een andere vector voor bank (meubel). Er is een vector voor tijdschrift (fysieke publicatie) en een andere voor tijdschrift (organisatie). Zoals je verwacht, gebruiken LLM's meer gelijksoortige vectoren voor polysemische betekenissen dan homonieme.
Tot nu toe hebben we nog niets gezegd over hoe taalmodellen dit doen - daar komen we zo op. Maar we benadrukken deze vectorvoorstellingen omdat het fundamenteel is om te begrijpen hoe taalmodellen werken.
Traditionele software is ontworpen om te werken met gegevens die eenduidig zijn. Als je een computer vraagt om "2 + 3" te berekenen, is er geen dubbelzinnigheid over wat 2, + of 3 betekenen. Maar natuurlijke taal zit vol dubbelzinnigheden die verder gaan dan homoniemen en polysemie:
- In "de klant vroeg de monteur om zijn auto te repareren", verwijst "zijn" naar de klant of naar de monteur?
- In "de professor drong er bij de student op aan haar huiswerk te maken", verwijst "haar" naar de professor of de student?
- In "fruit vliegt als een banaan" is "vliegen" een werkwoord (dat verwijst naar fruit dat door de lucht vliegt) of een zelfstandig naamwoord (dat verwijst naar insecten die van bananen houden)?
Mensen lossen dit soort dubbelzinnigheden op aan de hand van de context, maar er zijn geen eenvoudige of deterministische regels om dit te doen. Het vereist veeleer inzicht in feiten over de wereld. Je moet weten dat monteurs meestal de auto's van klanten repareren, dat studenten meestal hun eigen huiswerk maken en dat fruit meestal niet vliegt.
Woordvectoren bieden een flexibele manier voor taalmodellen om de precieze betekenis van elk woord in de context van een bepaalde passage weer te geven. Laten we nu eens kijken hoe ze dat doen.
Woordvectoren omzetten in woordvoorspellingen
GPT-3, een voorganger uit 2020 van de taalmodellen die ChatGPT aandrijven, is georganiseerd in tientallen lagen. Elke laag neemt een reeks vectoren als invoer - één vector voor elk woord in de ingevoerde tekst - en voegt informatie toe om de betekenis van dat woord te verduidelijken en beter te voorspellen welk woord daarna komt.
Laten we beginnen met een gestileerd Engelstalig voorbeeld:
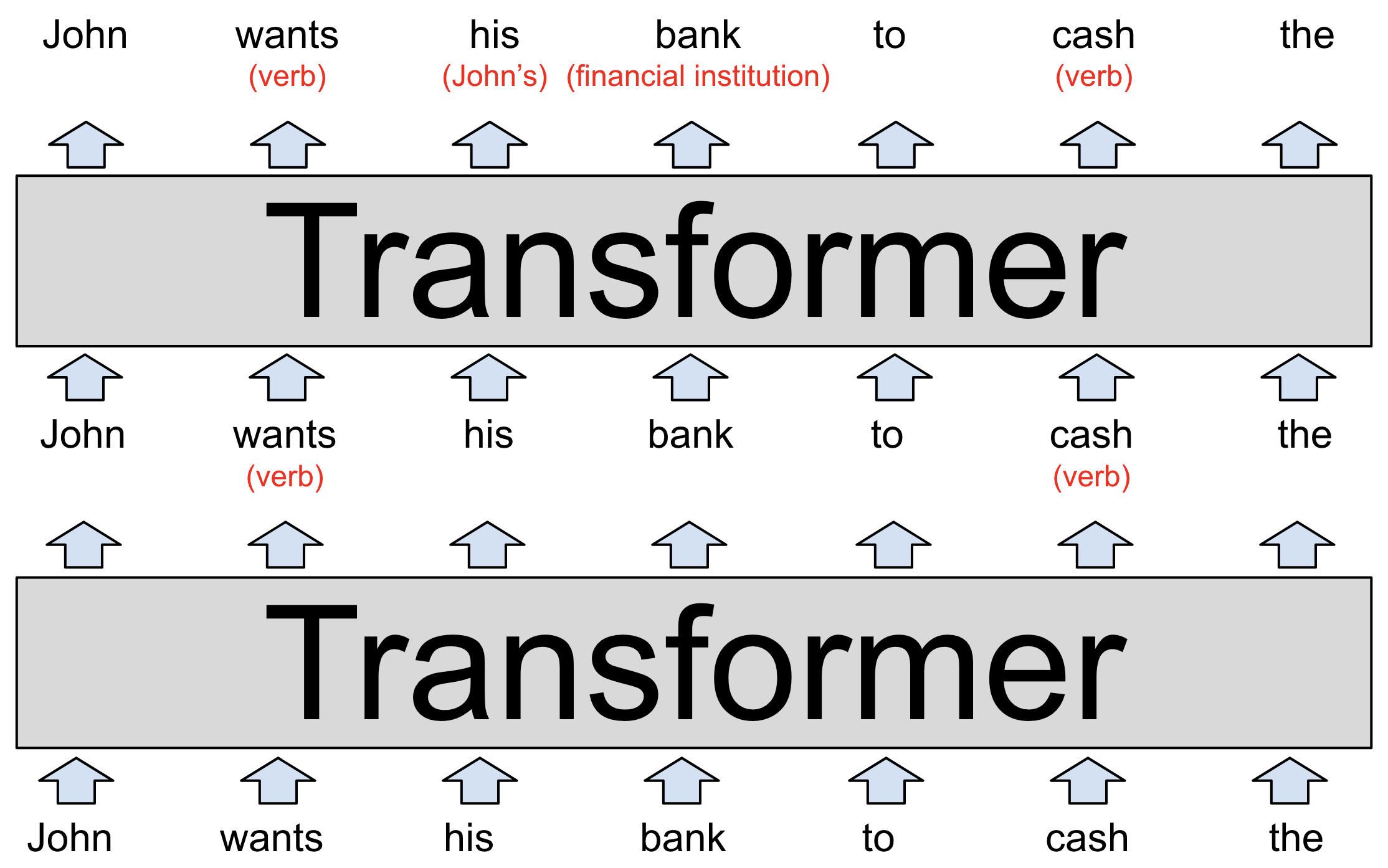 Fig. 3Elke laag van een LLM is een "transformer", een neurale netwerkarchitectuur die voor het eerst werd geïntroduceerd door Google in een baanbrekend artikel uit 2017.
Fig. 3Elke laag van een LLM is een "transformer", een neurale netwerkarchitectuur die voor het eerst werd geïntroduceerd door Google in een baanbrekend artikel uit 2017.
De invoer van het model, onderaan in het diagram, is de gedeeltelijke zin "John wil dat zijn bank de" verzilvert. Deze woorden, weergegeven als word2vec-stijl vectoren, worden ingevoerd in de eerste transformator.
De transformator komt erachter dat "wil" en "verzilvert" beide werkwoorden zijn (beide woorden kunnen ook zelfstandige naamwoorden zijn). We hebben deze toegevoegde context weergegeven als rode tekst tussen haakjes, maar in werkelijkheid zou het model dit opslaan door de woordvectoren te wijzigen op een manier die voor mensen moeilijk te interpreteren is. Deze nieuwe vectoren, bekend als een verborgen toestand, worden doorgegeven aan de volgende transformator in de stapel.
De tweede transformator voegt twee andere stukjes context toe: Het verduidelijkt dat "bank" verwijst naar een financiële instelling in plaats van een meubel, en dat "zijn" een voornaamwoord is dat verwijst naar John. De tweede transformator produceert nog een set verborgen toestandsvectoren die alles weergeven wat het model tot dan toe heeft geleerd.
Het bovenstaande diagram toont een puur hypothetische LLM, dus neem de details niet te serieus. We zullen zo meteen kijken naar onderzoek naar echte taalmodellen. Echte LLM's hebben meestal veel meer dan twee lagen. De krachtigste versie van GPT-3 heeft bijvoorbeeld 96 lagen.
Onderzoek suggereert dat de eerste paar lagen zich richten op het begrijpen van de zinsbouw en het oplossen van dubbelzinnigheden zoals we hierboven hebben laten zien. Latere lagen (die we niet laten zien om het diagram beheersbaar te houden) werken aan het ontwikkelen van een begrip op hoog niveau van de passage als geheel.
Als een LLM bijvoorbeeld een kort verhaal "doorleest", lijkt het allerlei informatie over de personages in het verhaal bij te houden: geslacht en leeftijd, relaties met andere personages, huidige en verleden locatie, persoonlijkheden en doelen, enzovoort.
Onderzoekers begrijpen niet precies hoe LLM's deze informatie bijhouden, maar logisch gezien moet het model dit doen door de verborgen toestandsvectoren aan te passen wanneer ze van de ene laag naar de volgende worden doorgegeven. Het helpt dat in moderne LLM's deze vectoren extreem groot zijn.
De krachtigste versie van GPT-3 gebruikt bijvoorbeeld woordvectoren met 12.288 dimensies, dat wil zeggen dat elk woord wordt weergegeven door een lijst van 12.288 getallen. Dat is 20 keer groter dan Google's word2vec schema uit 2013. Je kunt al die extra dimensies zien als een soort "krasruimte" die GPT-3 kan gebruiken om zichzelf notities te maken over de context van elk woord. Aantekeningen die door eerdere lagen zijn gemaakt, kunnen door latere lagen worden gelezen en aangepast, waardoor het model zijn begrip van de passage als geheel geleidelijk kan aanscherpen.
Dus stel dat we ons bovenstaande diagram veranderen in een taalmodel met 96 lagen dat een verhaal van 1000 woorden interpreteert. De 60e laag zou een vector voor "Jan" kunnen bevatten met een commentaar als "(hoofdpersoon, man, getrouwd met Brigitte, neef van Matthijs, uit Utrecht, momenteel in Breda, op zoek naar zijn vermiste portemonnee)". Nogmaals, al deze feiten (en waarschijnlijk nog veel meer) zouden op de een of andere manier worden gecodeerd als een lijst van 12.288 getallen die corresponderen met het woord Jan. Of misschien wordt een deel van deze informatie gecodeerd in de 12.288 dimensionale vectoren voor Brigitte, Matthijs, Breda, portemonnee of andere woorden in het verhaal.
Het doel is dat de 96e en laatste laag van het netwerk een verborgen toestand voor het laatste woord weergeeft die alle informatie bevat die nodig is om het volgende woord te voorspellen.
Mag ik even jullie aandacht?
Laten we het nu hebben over wat er in elke transformator gebeurt. De transformator heeft een proces in twee stappen voor het bijwerken van de verborgen toestand voor elk woord van de invoerpassage:
- In de aandachtsstap "kijken de woorden rond" naar andere woorden die een relevante context hebben en delen ze informatie met elkaar.
- In de feed-forward stap "denkt" elk woord na over de informatie die is verzameld in de vorige aandachtsstappen en probeert het het volgende woord te voorspellen.
Natuurlijk is het het netwerk, niet de individuele woorden, dat deze stappen uitvoert. Maar we formuleren het zo om te benadrukken dat transformatoren woorden, en niet hele zinnen of passages, als de basiseenheid van analyse behandelen. Dankzij deze aanpak kunnen LLM's optimaal profiteren van de enorme parallelle verwerkingskracht van moderne GPU-chips. En het helpt LLM's ook om te schalen naar passages met duizenden woorden. Dit zijn beide gebieden waar eerdere taalmodellen moeite mee hadden.
Je kunt het aandachtsmechanisme zien als een matchmaking service voor woorden. Elk woord maakt een checklist (een queryvector genoemd) die de kenmerken beschrijft van woorden waarnaar het op zoek is. Elk woord maakt ook een checklist (een sleutelvector genoemd) die zijn eigen kenmerken beschrijft. Het netwerk vergelijkt elke sleutelvector met elke queryvector (door een dotproduct te berekenen) om de woorden te vinden die het best overeenkomen. Zodra het een overeenkomst vindt, draagt het informatie over van het woord dat de sleutelvector produceerde naar het woord dat de queryvector produceerde.
In de vorige sectie lieten we bijvoorbeeld een hypothetische transformator zien die uitzoekt dat in de gedeeltelijke zin "Jan wil dat zijn bank de", "zijn" verwijst naar Jan. Hier is hoe dat er onder de motorkap uit zou kunnen zien. De zoekvector voor "zijn" zou effectief kunnen zeggen, "Ik zoek: een zelfstandig naamwoord dat een mannelijke persoon beschrijft." De sleutelvector voor "Jan" zou effectief kunnen zeggen, "Ik ben: een zelfstandig naamwoord dat een mannelijk persoon beschrijft". Het netwerk zou detecteren dat deze twee vectoren overeenkomen en informatie over de vector voor "Jan" verplaatsen naar de vector voor "zijn".
Elke aandachtslaag heeft meerdere "aandachtskoppen", wat betekent dat dit informatieverwisselingsproces meerdere keren (parallel) plaatsvindt in elke laag. Elke aandachtskop richt zich op een andere taak:
- Eén aandachtskop kan voornaamwoorden met zelfstandige naamwoorden matchen, zoals we hierboven bespraken.
- Een ander aandachtshoofd kan werken aan het oplossen van de betekenis van homoniemen zoals "bank".
- Een derde aandachtskop koppelt zinnen van twee woorden aan elkaar, zoals "Jan Schalkwijk".
Enzovoort.
Aandachtskoppen werken vaak na elkaar, waarbij de resultaten van een aandachtsoperatie in de ene laag een input worden voor een aandachtskop in een volgende laag. Voor elk van de taken die we hierboven hebben opgesomd, kunnen gemakkelijk meerdere aandachtskoppen nodig zijn in plaats van slechts één.
De grootste versie van GPT-3 heeft 96 lagen met elk 96 aandachtskoppen, dus GPT-3 voert 9.216 aandachtsoperaties uit elke keer dat het een nieuw woord voorspelt.
Een voorbeeld uit de praktijk
In de laatste twee hoofdstukken hebben we een gestileerde versie van de werking van aandachtshoofden gepresenteerd. Laten we nu eens kijken naar onderzoek naar de innerlijke werking van een echt taalmodel. Vorig jaar bestudeerden wetenschappers van Redwood Research hoe GPT-2, een voorloper van ChatGPT, het volgende woord voorspelde voor de passage "Toen Marie en Jan naar de winkel gingen, gaf Jan een drankje aan."
GPT-2 voorspelde dat het volgende woord Marie was. De onderzoekers ontdekten dat drie soorten aandachtshoofden bijdroegen aan deze voorspelling:
- Drie hoofden die ze "Name Mover Heads" noemden, kopieerden informatie van de Marie vector naar de uiteindelijke input vector (voor het woord "aan"). GPT-2 gebruikt de informatie in deze meest rechtse vector om het volgende woord te voorspellen.
- Hoe heeft het netwerk besloten dat Marie het juiste woord was om te kopiëren? Door terug te werken in het rekenproces van GPT-2 vonden de wetenschappers een groep van vier aandachtskoppen die ze "Subject Inhibition Heads" noemden en die de tweede Jan vector markeerden op een manier die de "Name Mover Heads" ervan weerhield de naam Jan te kopiëren.
- Hoe wisten de Subject Inhibition Heads dat Jan niet gekopieerd mocht worden? Verder terugwerkend vond het team twee aandachtshoofden die ze Duplicate Token Heads noemden. Zij markeerden de tweede Jan vector als een duplicaat van de eerste Jan vector, wat de Subject Inhibitie Hoofden hielp te beslissen dat Jan niet gekopieerd mocht worden.
Kortom, deze negen aandachtshoofden stelden GPT-2 in staat om uit te zoeken dat "Jan gaf een drankje aan Jan" geen zin heeft en in plaats daarvan te kiezen voor "Jan gaf een drankje aan Marie".
We houden van dit voorbeeld omdat het illustreert hoe moeilijk het zal zijn om LLM's volledig te begrijpen. Het vijfkoppige Redwood-team publiceerde een artikel van 25 pagina's waarin ze uitlegden hoe ze deze aandachtshoofden identificeerden en valideerden. Maar zelfs na al dat werk hebben we nog lang geen volledige verklaring waarom GPT-2 besloot om "Marie" te voorspellen als het volgende woord.
Hoe wist het model bijvoorbeeld dat het volgende woord iemands naam moest zijn en niet een ander soort woord? Het is makkelijk om vergelijkbare zinnen te bedenken waarin Maria geen goede voorspelling zou zijn voor het volgende woord. Bijvoorbeeld, in de zin "toen Marie en Jan naar het restaurant gingen, gaf Jan zijn sleutels aan", zouden de logische volgende woorden "de bediende" zijn.
Vermoedelijk kunnen computerwetenschappers met genoeg onderzoek meer stappen in het redeneerproces van GPT-2 ontdekken en verklaren. Uiteindelijk zouden ze een volledig begrip kunnen ontwikkelen van hoe GPT-2 besloot dat Marie het meest waarschijnlijke volgende woord voor deze zin is. Maar het kan maanden of zelfs jaren duren om de voorspelling van één enkel woord te begrijpen.
De taalmodellen die ten grondslag liggen aan ChatGPT zijn aanzienlijk groter en complexer dan GPT-2. Ze zijn in staat tot complexere redeneringen dan de eenvoudige zinaanvullingstaak die het Redwood-team bestudeerde. Volledig verklaren hoe deze systemen werken zal dus een enorm project zijn dat niet snel zal worden voltooid.
De feed-forward stap
Nadat de aandachtskoppen informatie hebben overgedragen tussen woordvectoren, is er een feed-forward netwerk dat "nadenkt" over elke woordvector en het volgende woord probeert te voorspellen. In dit stadium wordt er geen informatie uitgewisseld tussen woorden: de feed-forward laag analyseert elk woord afzonderlijk. De feed-forward laag heeft echter wel toegang tot alle informatie die eerder werd overgenomen door een aandachtskop.
Hier is de structuur van de feed-forward laag in de grootste versie van GPT-3:
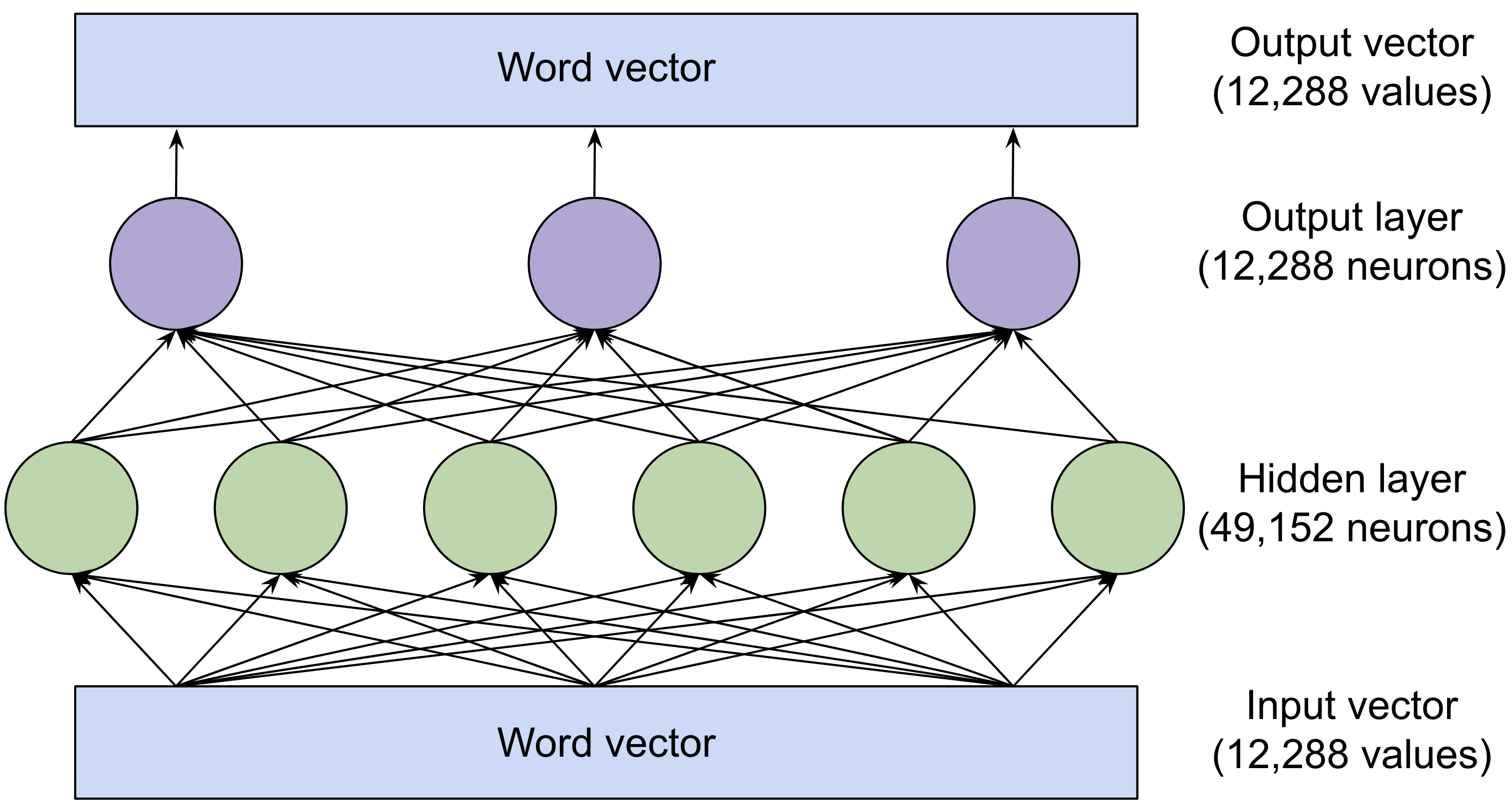 Fig. 4De groene en paarse cirkels zijn neuronen, wiskundige functies die een gewogen som van hun invoer berekenen. (De som wordt vervolgens doorgegeven aan een activatiefunctie. Bekijk de neurale netwerk uitleg van 2018 als je een volledige uitleg wilt over hoe dit werkt).
Fig. 4De groene en paarse cirkels zijn neuronen, wiskundige functies die een gewogen som van hun invoer berekenen. (De som wordt vervolgens doorgegeven aan een activatiefunctie. Bekijk de neurale netwerk uitleg van 2018 als je een volledige uitleg wilt over hoe dit werkt).
Wat de feed-forward laag krachtig maakt, is het enorme aantal verbindingen. We hebben dit netwerk getekend met drie neuronen in de uitvoerlaag en zes neuronen in de verborgen laag, maar de feed-forward lagen van GPT-3 zijn veel groter: 12.288 neuronen in de uitvoerlaag (wat overeenkomt met de 12.288-dimensionale woordvectoren van het model) en 49.152 neuronen in de verborgen laag.
Dus in de grootste versie van GPT-3 zijn er 49.152 neuronen in de verborgen laag, met 12.288 ingangen (en dus 12.288 gewichtsparameters) voor elk neuron. En er zijn 12.288 uitgangsneuronen met 49.152 ingangswaarden (en dus 49.152 gewichtsparameters) voor elke neuron. Dit betekent dat elke feed-forward laag 49.152 * 12.288 + 12.288 * 49.152 = 1,2 miljard gewichtsparameters heeft. En er zijn 96 feed-forward lagen, voor een totaal van 1,2 miljard * 96 = 116 miljard parameters! Dit is bijna tweederde van het totaal van 175 miljard parameters van GPT-3.
In een paper uit 2020 ontdekten onderzoekers van de Tel Aviv University dat "feed-forward lagen" werken door patronen te matchen: elke neuron in de verborgen laag matcht met een specifiek patroon in de ingevoerde tekst.
Hier zijn enkele van de patronen die werden gematcht door neuronen in een 16-lagen versie van GPT-2:
- Een neuron in laag 1 matchte opeenvolgingen van woorden die eindigen op "substituten".
- Een neuron in laag 6 matchte opeenvolgingen van woorden die gerelateerd waren aan het leger en eindigden op "base" of "bases".
- Een neuron in laag 13 matchte reeksen die eindigden met een tijdsbereik zoals "tussen 15.00 en 19.00 uur" of "vanaf 19.00 uur vrijdag tot".
- Een neuron in laag 16 matchte reeksen die gerelateerd waren aan televisieprogramma's zoals "de originele NBC-dagversie, gearchiveerd" of "kijktijdverschuiving voegde 57% toe aan de aflevering".
Zoals je kunt zien, worden de patronen abstracter in de latere lagen. De vroege lagen kwamen meestal overeen met specifieke woorden, terwijl latere lagen overeenkwamen met zinnen die in bredere semantische categorieën vielen, zoals televisieprogramma's of tijdsintervallen.
Dit is interessant omdat, zoals eerder vermeld, de feed-forward laag slechts één woord per keer onderzoekt. Dus wanneer de sequentie "de originele NBC-dagversie, gearchiveerd" wordt geclassificeerd als gerelateerd aan televisie, heeft deze alleen toegang tot de vector voor gearchiveerd, niet tot woorden als NBC of dag. Vermoedelijk kan de feed-forward laag zien dat "gearchiveerd" deel uitmaakt van een televisie-gerelateerde sequentie omdat aandachtshoofden eerder contextuele informatie naar de gearchiveerde vector hebben verplaatst.
Wanneer een neuron met een van deze patronen overeenkomt, voegt het informatie toe aan de woordvector. Hoewel deze informatie niet altijd gemakkelijk te interpreteren is, kun je het in veel gevallen zien als een voorlopige voorspelling over het volgende woord.
Feed-forward netwerken redeneren met vectorwiskunde
Recent onderzoek van Brown University onthulde een elegant voorbeeld van hoe feed-forward lagen helpen om het volgende woord te voorspellen. Eerder bespraken we Google's word2vec onderzoek waaruit bleek dat het mogelijk was om vectorrekenkunde te gebruiken om analoog te redeneren. Bijvoorbeeld Berlijn - Duitsland + Frankrijk = Parijs.
De onderzoekers van Brown ontdekten dat feed-forward lagen soms precies deze methode gebruiken om het volgende woord te voorspellen. Ze onderzochten bijvoorbeeld hoe GPT-2 reageerde op de volgende vraag:
"V: Wat is de hoofdstad van Frankrijk? A: Parijs V: Wat is de hoofdstad van Polen? A:"
Het team bestudeerde een versie van GPT-2 met 24 lagen. Na elke laag tastten de Brown-wetenschappers het model af om te zien wat de beste gok was voor de volgende token. In de eerste 15 lagen was de beste gok een schijnbaar willekeurig woord. Tussen de 16e en 19e laag begon het model te voorspellen dat het volgende woord Polen zou zijn - niet correct, maar wel steeds beter. Toen, bij de 20e laag, veranderde de bovenste gok in Warschau - het juiste antwoord - en dat bleef zo in de laatste vier lagen.
De Brown-onderzoekers ontdekten dat de 20e feed-forward laag Polen in Warschau veranderde door een vector toe te voegen die landvectoren aan hun bijbehorende hoofdsteden koppelt. Het toevoegen van dezelfde vector aan China leverde Peking op. Feed-forward lagen in hetzelfde model gebruikten vectorrekenkunde om kleine letters om te zetten in hoofdletters en tegenwoordige tijd woorden in hun verleden tijd equivalenten.
De aandachts- en feed-forward lagen hebben verschillende taken
Tot nu toe hebben we gekeken naar twee echte voorbeelden van GPT-2 woordvoorspellingen: aandachtskoppen die helpen voorspellen dat Jan Brigitte iets te drinken gaf en een feed-forward laag die helpt voorspellen dat Warschau de hoofdstad van Polen is.
In het eerste geval kwam "Brigitte" van de door de gebruiker gegeven prompt. Maar in het tweede geval stond "Warschau" niet in de prompt. In plaats daarvan moest GPT-2 het feit dat Warschau de hoofdstad van Polen was "onthouden" - informatie die het had geleerd van trainingsgegevens.
Toen de Brown-onderzoekers de feed-forward laag uitschakelden die Polen in Warschau omzette, voorspelde het model niet langer Warschau als het volgende woord. Maar interessant genoeg, als ze vervolgens de zin "De hoofdstad van Polen is Warschau" toevoegden aan het begin van de prompt, dan kon GPT-2 de vraag weer beantwoorden. Dit komt waarschijnlijk doordat GPT-2 aandachtshoofden gebruikte om de naam Warschau van eerder in de prompt over te nemen.
Deze taakverdeling geldt meer in het algemeen:
Aandachtskoppen halen informatie op uit eerdere woorden in een prompt, terwijl feed-forward lagen taalmodellen in staat stellen om informatie te "onthouden" die niet in de prompt staat.
Een manier om de feed-forward lagen te zien is als een database van informatie die het model heeft geleerd van de trainingsdata. De eerdere feed-forward lagen coderen eerder eenvoudige feiten die gerelateerd zijn aan specifieke woorden, zoals "Trump komt vaak na Donald." Latere lagen coderen complexere relaties zoals "voeg deze vector toe om een land om te zetten naar zijn hoofdstad".
Hoe taalmodellen worden getraind
Veel vroege algoritmen voor machinaal leren vereisten dat trainingsvoorbeelden met de hand werden gelabeld door mensen. Trainingsgegevens konden bijvoorbeeld foto's van honden of katten zijn met een door mensen verstrekt label ("hond" of "kat") voor elke foto. De noodzaak voor mensen om gegevens te labelen maakte het moeilijk en duur om datasets te maken die groot genoeg waren om krachtige modellen te trainen.
Een belangrijke innovatie van LLM's is dat ze geen expliciet gelabelde gegevens nodig hebben. In plaats daarvan leren ze door te proberen het volgende woord in gewone tekstpassages te voorspellen. Bijna elke geschreven tekst - van Wikipedia-pagina's tot nieuwsartikelen tot computercode - is geschikt om deze modellen te trainen.
Een LLM kan bijvoorbeeld de input "Ik heb mijn koffie graag met melk en" krijgen en in staat zijn om "suiker" te voorspellen als het volgende woord. Een nieuw geïnitialiseerd taalmodel zal hier heel slecht in zijn, omdat elk van de gewichtsparameters - 175 miljard in de krachtigste versie van GPT-3 - begint als een in wezen willekeurig getal. Maar naarmate het model meer voorbeelden ziet - honderden miljarden woorden - worden die gewichten geleidelijk aangepast om steeds betere voorspellingen te doen.
Voorbeeld
Hier is een voorbeeld om te illustreren hoe dit werkt. Stel, je gaat douchen en je wilt dat de temperatuur precies goed is: niet te warm en niet te koud. Je hebt deze kraan nog nooit gebruikt, dus richt je de knop in een willekeurige richting en voel je de temperatuur van het water. Als het te warm is, draai je hem de ene kant op; als het te koud is, draai je hem de andere kant op. Hoe dichter je bij de juiste temperatuur komt, hoe kleiner de aanpassingen die je maakt.
Laten we nu een paar veranderingen aanbrengen in de analogie. Stel je eerst voor dat er 50.257 kranen zijn in plaats van slechts één. Elke kraan komt overeen met een ander woord zoals "de", "kat" of "bank". Je doel is om alleen water uit de kraan te laten komen die overeenkomt met het volgende woord in een reeks.
Ten tweede is er een wirwar van onderling verbonden leidingen achter de kranen, en op deze leidingen zitten ook een heleboel kleppen. Dus als er water uit de verkeerde kraan komt, stel je niet gewoon de knop bij de kraan bij. Je stuurt een leger intelligente "eekhoorns" erop uit om elke leiding terug te volgen en elke klep die ze onderweg tegenkomen bij te stellen.
Dit wordt ingewikkeld omdat dezelfde leiding vaak naar meerdere kranen loopt. Er moet dus goed worden nagedacht over welke kleppen strakker moeten en welke losser, en met hoeveel. Uiteraard wordt dit voorbeeld al snel dwaas als je het te letterlijk neemt. Het zou niet realistisch of nuttig zijn om een netwerk van leidingen te bouwen met 175 miljard kleppen. Maar dankzij de Wet van Moore kunnen computers op deze schaal werken en dat gebeurt ook.
Alle onderdelen van LLM's die we tot nu toe in dit artikel hebben besproken - de neuronen in de feed-forward lagen en de aandachtskoppen die contextuele informatie tussen woorden verplaatsen - zijn geïmplementeerd als een keten van eenvoudige wiskundige functies (meestal matrixvermenigvuldigingen) waarvan het gedrag wordt bepaald door instelbare gewichtsparameters. Net zoals de eekhoorns in mijn verhaal de kleppen los- en vastdraaien om de waterstroom te regelen, zo verhoogt of verlaagt het trainingsalgoritme de gewichtsparameters van het taalmodel om te regelen hoe informatie door het neurale netwerk stroomt.
| Meer lezen? Hoe computers schokkend goed werden in het herkennen van afbeeldingen |
Het trainingsproces verloopt in twee stappen. Eerst is er een "voorwaartse stap", waarbij het water wordt aangezet en je controleert of het uit de juiste kraan komt. Dan wordt het water uitgezet en is er een "achterwaartse stap" waarbij de eekhoorns langs elke leiding racen om kleppen vast en los te draaien. In digitale neurale netwerken wordt de rol van de eekhoorns gespeeld door een algoritme dat backpropagatie wordt genoemd. Dit algoritme "loopt terug" door het netwerk en gebruikt berekeningen om in te schatten hoeveel elke gewichtsparameter moet worden veranderd. (Als je meer wilt weten over backpropagation, bekijk dan onze uitleg uit 2018 over hoe neurale netwerken werken).
Om dit proces te voltooien - een voorwaartse beweging met één voorbeeld en vervolgens een achterwaartse beweging om de prestaties van het netwerk op dat voorbeeld te verbeteren - zijn honderden miljarden wiskundige bewerkingen nodig. En het trainen van een model zo groot als GPT-3 vereist het herhalen van het proces over vele, vele voorbeelden. OpenAI schat dat er meer dan 300 miljard biljoen berekeningen met drijvende komma nodig waren om GPT-3 te trainen-dat is maanden werk voor tientallen high-end computerchips.
De verrassende prestaties van GPT-3
Misschien vind je het verrassend dat het trainingsproces zo goed werkt. ChatGPT kan allerlei complexe taken uitvoeren: essays schrijven, analogieën tekenen en zelfs computercode schrijven. Hoe kan zo'n eenvoudig leermechanisme dan zo'n krachtig model opleveren?
Eén reden is schaal. Het is moeilijk om het aantal voorbeelden dat een model als GPT-3 ziet te overschatten. GPT-3 werd getraind op een corpus van ongeveer 500 miljard woorden. Ter vergelijking: een typisch menselijk kind krijgt op zijn 10e ongeveer 100 miljoen woorden te zien.
De afgelopen vijf jaar heeft OpenAI de omvang van zijn taalmodellen gestaag vergroot. In een veelgelezen artikel uit 2020 rapporteerde OpenAI dat de nauwkeurigheid van zijn taalmodellen schaalde "als een power-law met de grootte van het model, de grootte van de dataset en de hoeveelheid rekenkracht gebruikt voor training, met sommige trends die meer dan zeven orden van grootte beslaan".
Hoe groter hun modellen werden, hoe beter ze waren in taaltaken. Maar dit gold alleen als ze de hoeveelheid trainingsgegevens met een vergelijkbare factor verhoogden. En om grotere modellen te trainen op meer data heb je veel meer rekenkracht nodig.
OpenAI's eerste LLM, GPT-1, werd uitgebracht in 2018. Het gebruikte 768-dimensionale woordvectoren en had 12 lagen voor een totaal van 117 miljoen parameters. Een paar maanden later bracht OpenAI GPT-2 uit. De grootste versie had 1600-dimensionale woordvectoren, 48 lagen en een totaal van 1,5 miljard parameters.
In 2020 bracht OpenAI GPT-3 uit, met 12.288-dimensionale woordvectoren en 96 lagen, voor een totaal van 175 miljard parameters. Dit jaar bracht OpenAI GPT-4 uit. Het bedrijf heeft geen architecturale details gepubliceerd, maar er wordt algemeen aangenomen dat GPT-4 aanzienlijk groter is dan GPT-3. Elk model leerde niet alleen meer feiten dan zijn kleinere voorgangers, het presteerde ook beter op taken die een vorm van abstract redeneren vereisen.
Neem bijvoorbeeld het volgende verhaal:
|
Er is een zak gevuld met popcorn. Er zit geen chocolade in de zak. Toch staat er op het label van de zak "chocolade" en niet "popcorn". |
Je kunt waarschijnlijk wel raden dat Sandra denkt dat de zak chocolade bevat en dat ze verrast zal zijn als er popcorn in zit. Psychologen noemen dit vermogen om te redeneren over de mentale toestand van andere mensen "theory-of-mind". De meeste mensen hebben dit vermogen al vanaf de lagere school. Experts zijn het er niet over eens of niet-menselijke dieren (zoals chimpansees) een "theory-of-mind" (ToM) hebben, maar er is algemene consensus dat het belangrijk is voor de menselijke sociale cognitie.
Eerder dit jaar publiceerde Stanford psycholoog Michal Kosinski een onderzoek naar het vermogen van LLM's om theory-of-mind taken op te lossen. Hij gaf verschillende taalmodellen passages zoals degene die we hierboven citeerden en vroeg ze vervolgens om een zin af te maken als "ze gelooft dat de tas vol zit met". Het juiste antwoord is "chocolade", maar een onontwikkeld taalmodel zou "popcorn" of iets anders kunnen zeggen.
GPT-1 en GPT-2 zakten voor deze test. Maar de eerste versie van GPT-3, uitgebracht in 2020, had het in bijna 40% van de gevallen bij het juiste eind - een prestatieniveau dat Kosinski vergelijkt met dat van een 3-jarige. De laatste versie van GPT-3, die afgelopen november werd uitgebracht, verbeterde dit tot ongeveer 90 procent - vergelijkbaar met een 7-jarige. GPT-4 beantwoordde ongeveer 95 procent van de theory-of-mind vragen correct.
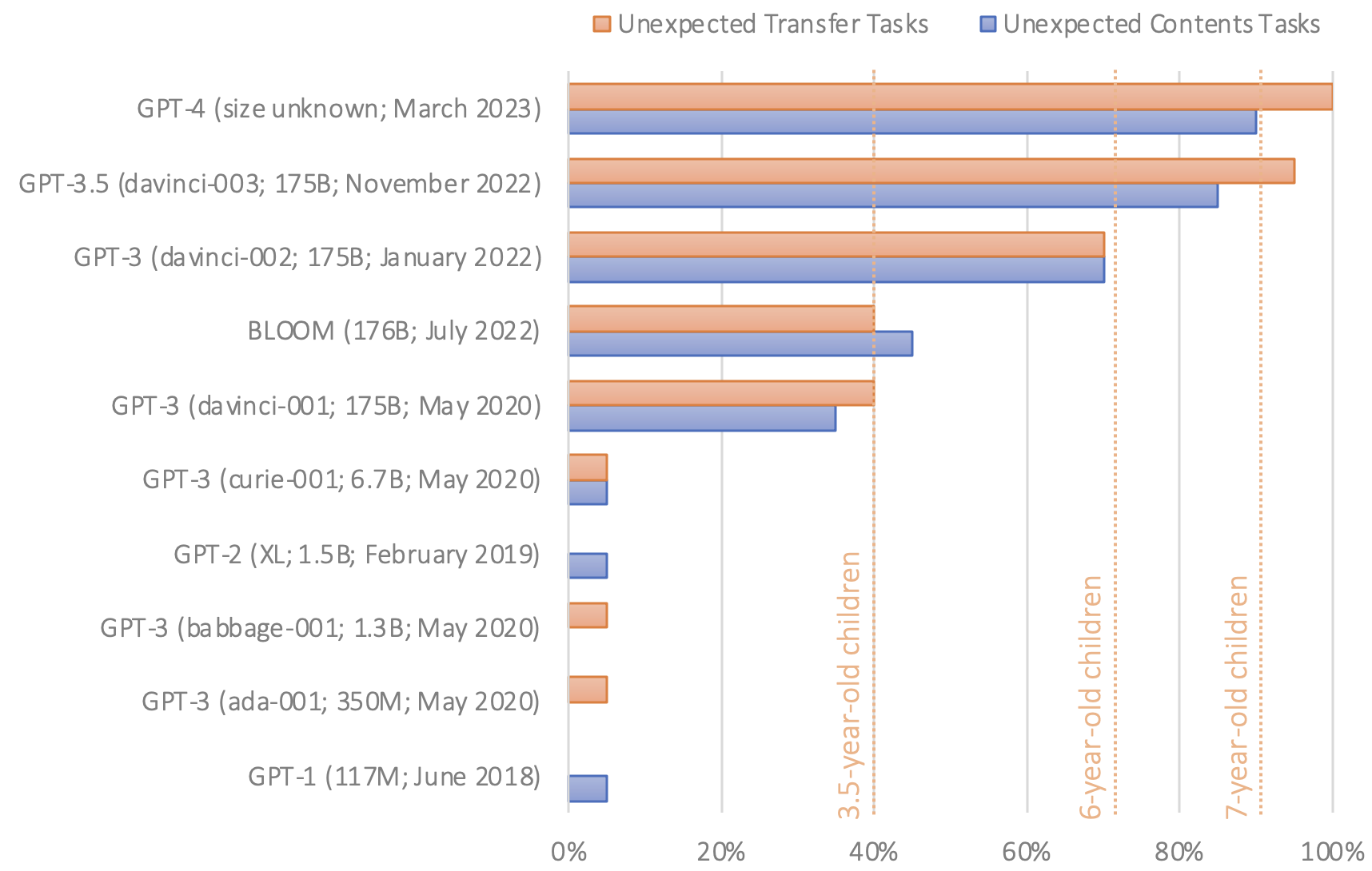 Fig. 5"Gezien het feit dat er geen indicatie is dat ToM-achtige bekwaamheid opzettelijk in deze modellen is ingebouwd, noch onderzoek dat aantoont dat wetenschappers weten hoe ze dat moeten bereiken, is ToM-achtige bekwaamheid waarschijnlijk spontaan en autonoom ontstaan, als een bijproduct van de toenemende taalvaardigheid van de modellen," schreef Kosinski.
Fig. 5"Gezien het feit dat er geen indicatie is dat ToM-achtige bekwaamheid opzettelijk in deze modellen is ingebouwd, noch onderzoek dat aantoont dat wetenschappers weten hoe ze dat moeten bereiken, is ToM-achtige bekwaamheid waarschijnlijk spontaan en autonoom ontstaan, als een bijproduct van de toenemende taalvaardigheid van de modellen," schreef Kosinski.
Het is vermeldenswaard dat onderzoekers het er niet allemaal over eens zijn dat deze resultaten duiden op bewijs van theory-of-mind; kleine veranderingen in de "false-belief" taak leidden bijvoorbeeld tot veel slechtere prestaties van GPT-3, en GPT-3 vertoont meer variabele prestaties in andere taken die theory-of-mind meten. Zoals een van ons (Sean) heeft geschreven, kan het zijn dat succesvolle prestaties toe te schrijven zijn aan verstoringen in de taak een soort "slimme Hans" effect, alleen dan in taalmodellen in plaats van paarden.
Desalniettemin zouden de bijna-menselijke prestaties van GPT-3 op verschillende taken die zijn ontworpen om de theorie van het verstand te meten een paar jaar geleden ondenkbaar zijn geweest - en het is consistent met het idee dat grotere modellen over het algemeen beter zijn in taken die redeneren op hoog niveau vereisen.
Dit is slechts een van de vele voorbeelden van taalmodellen die spontaan redeneercapaciteiten op hoog niveau lijken te ontwikkelen. In april publiceerden onderzoekers van Microsoft een artikel waarin ze stelden dat GPT-4 vroege, prikkelende hints vertoonde van kunstmatige algemene intelligentie - het vermogen om op een verfijnde, mensachtige manier te denken.
Een onderzoeker vroeg GPT-4 bijvoorbeeld om een Eenhoorn te tekenen met behulp van een obscure grafische programmeertaal genaamd TiKZ. GPT-4 antwoordde met een paar regels code die de onderzoeker vervolgens invoerde in de TiKZ-software. De resulterende afbeeldingen waren ruw, maar lieten duidelijk zien dat GPT-4 enig begrip had van hoe eenhoorns eruit zien.
 Fig. 6De onderzoekers dachten dat GPT-4 op de een of andere manier de code voor het tekenen van een Eenhoorn had onthouden uit zijn trainingsgegevens, dus gaven ze het een vervolguitdaging: ze veranderden de eenhoorncode om de hoorn te verwijderen en enkele andere lichaamsdelen te verplaatsen. Daarna vroegen ze GPT-4 om de hoorn er weer op te zetten. GPT-4 reageerde door de hoorn op de juiste plek te zetten:
Fig. 6De onderzoekers dachten dat GPT-4 op de een of andere manier de code voor het tekenen van een Eenhoorn had onthouden uit zijn trainingsgegevens, dus gaven ze het een vervolguitdaging: ze veranderden de eenhoorncode om de hoorn te verwijderen en enkele andere lichaamsdelen te verplaatsen. Daarna vroegen ze GPT-4 om de hoorn er weer op te zetten. GPT-4 reageerde door de hoorn op de juiste plek te zetten:
 Fig. 7
Fig. 7
GPT-4 was hiertoe in staat, ook al waren de trainingsgegevens voor de door de auteurs geteste versie volledig gebaseerd op tekst. Er zaten dus geen afbeeldingen in de trainingsset. Maar GPT-4 heeft blijkbaar geleerd om te redeneren over de vorm van het lichaam van een Eenhoorn na training op een enorme hoeveelheid geschreven tekst.
Op dit moment hebben we geen echt inzicht in hoe LLM's dit soort prestaties leveren. Sommige mensen beweren dat zulke voorbeelden aantonen dat de modellen de betekenis van de woorden in hun trainingsset echt beginnen te begrijpen. Anderen houden vol dat taalmodellen "stochastische papegaaien" zijn die alleen maar steeds complexere woordreeksen herhalen zonder ze echt te begrijpen.
Dit debat wijst op een diepe filosofische spanning die misschien onmogelijk op te lossen is. Desalniettemin denken wij dat het belangrijk is om ons te richten op de empirische prestaties van modellen zoals GPT-3. Als een taalmodel consistent het juiste antwoord kan geven op een bepaald type vraag, en als onderzoekers er zeker van zijn dat ze hebben gecontroleerd voor verstoringen (bijvoorbeeld door ervoor te zorgen dat het taalmodel niet werd blootgesteld aan die vragen tijdens de training), dan is dat een interessant en belangrijk resultaat, of het model taal nu wel of niet begrijpt in precies dezelfde zin als mensen dat doen.
Een andere mogelijke reden dat trainen met "next-token prediction" zo goed werkt, is dat taal zelf voorspelbaar is. Regelmatigheden in taal zijn vaak (maar niet altijd) verbonden met regelmatigheden in de fysieke wereld. Dus als een taalmodel leert over relaties tussen woorden, leert het vaak impliciet ook over relaties in de wereld.
Verder is voorspellen mogelijk van fundamenteel belang voor zowel biologische als kunstmatige intelligentie. Volgens filosofen als Andy Clark kunnen we het menselijk brein beschouwen als een "voorspellingsmachine" die als belangrijkste taak heeft om voorspellingen te doen over onze omgeving die vervolgens gebruikt kunnen worden om succesvol door die omgeving te navigeren. Intuïtief is het maken van goede voorspellingen gebaat bij goede voorstellingen - je hebt meer kans om succesvol te navigeren met een nauwkeurige kaart dan met een onnauwkeurige kaart. De wereld is groot en complex en het maken van voorspellingen helpt organismen om zich efficiënt te oriënteren en aan te passen aan die complexiteit.
Traditioneel was een grote uitdaging bij het bouwen van taalmodellen het uitzoeken van de meest bruikbare manier om verschillende woorden weer te geven - vooral omdat de betekenis van veel woorden sterk afhankelijk is van de context. Met de voorspelling van het volgende woord kunnen onderzoekers deze lastige theoretische puzzel omzeilen door er een empirisch probleem van te maken. Het blijkt dat als we genoeg gegevens en rekenkracht beschikbaar stellen, taalmodellen uiteindelijk veel leren over hoe menselijke taal werkt door simpelweg uit te zoeken hoe ze het volgende woord het beste kunnen voorspellen. Het nadeel is dat we eindigen met systemen waarvan we de innerlijke werking niet volledig begrijpen.
Dit artikel is geheel gebaseerd op het Engelstalige artikel: A jargon-free explanation of how AI large language models work
De auteurs zijn:
- Tim Lee werkte van 2017 tot 2021 bij Ars. Hij lanceerde onlangs een nieuwe nieuwsbrief, Understanding AI. Hierin wordt onderzocht hoe AI werkt en hoe het onze wereld verandert. Je kunt je hier abonneren op zijn nieuwsbrief.
- Sean Trott is assistent-professor aan de University of California, San Diego, waar hij onderzoek doet naar taalbegrip bij mensen en grote taalmodellen. Hij schrijft over deze en andere onderwerpen in zijn nieuwsbrief The Counterfactual.