
Inleiding
Donderdagmiddag ging de telefoon: onbekend nummer uit Amsterdam. Toch maar opgenomen en het bleek Bart van RTL4.
“In België gebruiken ze een computer om te meten of ouderen eenzaam zijn. Kunnen jullie dat ook? En zouden jullie hieraan willen meewerken?”
Zo ongeveer begonnen 24 zeer hectische uren waarin zowel de onderzoekers van de UTwente als die van Telecats hard bezig zijn geweest om op tijd (voor vrijdagavond 18:15) te begrijpen wat nu precies de bedoeling was, vervolgens een aantal relevante demo’s klaar te zetten, ruimtes voor de verschillende interviews te reserveren en natuurlijk om de gesprekken bij de UTwente en Telecats plus wat sfeerbeelden op te nemen.
 Fig. 1: voorkant van het ietwat tendentieuze artikel in de De Standaard over het "opsporen van eenzame bejaarden".
Fig. 1: voorkant van het ietwat tendentieuze artikel in de De Standaard over het "opsporen van eenzame bejaarden".
Aanleiding
Maar hoe kwamen ze nu op dit onderwerp? In de Vlaamse Standaard stond op donderdagochtend een intrigerend artikel over “het opsporen van eenzame bejaarden”. Het betrof een gezamenlijk project van het callcenter van Sebeco dat ouderen belt en de ELIS-groep van de UGent die software heeft ontwikkeld om realtime het gesprek te monitoren.
 Fig. 2: Kris Demuynck, hoogleraar spraak- en audioverwerking aan de UGent. De software probeert in te schatten in hoeverre de spraak van de ouderen afwijkt van “normaal”. Als dat zo is, dan krijgt de medewerker een seintje en kan hij/zij proberen door te vragen. De vragen zijn semi-standaard vragen en zijn bedoeld om erachter te komen of alles wel goed gaat met de gebelde ouderen. Hiermee kun je er dus achter komen of een oudere inderdaad niet eenzaam is of dat hij/zij slechts een sociaal gewenst antwoord geeft. Super nuttig maar het is nog niet hetzelfde als het detecteren van eenzaamheid onder ouderen, laat staan het detecteren van eenzame bejaarden.
Fig. 2: Kris Demuynck, hoogleraar spraak- en audioverwerking aan de UGent. De software probeert in te schatten in hoeverre de spraak van de ouderen afwijkt van “normaal”. Als dat zo is, dan krijgt de medewerker een seintje en kan hij/zij proberen door te vragen. De vragen zijn semi-standaard vragen en zijn bedoeld om erachter te komen of alles wel goed gaat met de gebelde ouderen. Hiermee kun je er dus achter komen of een oudere inderdaad niet eenzaam is of dat hij/zij slechts een sociaal gewenst antwoord geeft. Super nuttig maar het is nog niet hetzelfde als het detecteren van eenzaamheid onder ouderen, laat staan het detecteren van eenzame bejaarden.
In een telefonisch vraaggesprek gaf Kris Demuynck, hoogleraar spraak- en audioverwerking aan de UGent bovendien aan dat er geen spraakherkenning wordt gebruikt. Het gaat om oudere mensen en die zijn sowieso lastiger te herkennen en bovendien spreken ze veel vaker met een behoorlijk accent zo niet in een dialect.
Emotie in spraak: waarom?
Noch op de UTwente noch bij Telecats hebben we software die iets vergelijkbaars doet, maar we doen wel onderzoek naar “emotie in spraak”. Op de UTwente is dit belangrijk voor het ontwikkelen van sociale robots. Wil je robots enigszins vrij aan de menselijke samenleving laten deelnemen, dan moeten ze een minimaal “besef” van emotie hebben.
Bij Telecats krijgen ze steeds weer vragen van opdrachtgevers: kunnen jullie meeluisteren met gesprekken en aangeven wanneer het gesprek misloopt zodat een supervisor kan ingrijpen en kunnen jullie over grote hoeveelheden gesprekken aangeven hoe vaak men tevreden of ontevreden is? Wat is kortom het sentiment in de telefonische gesprekken?
Het onderzoek naar het detecteren van Emotie in Spraak (EiS) en het gebruik van manieren om dit enigszins te kunnen bepalen wordt al geruime tijd in Twente gedaan. Op de UTwente is het vooral dr. Khiet Truong die daaraan werkt. Bij Telecats zijn het vooral oud-studenten van de HMI-groep ?.
Stand van zaken
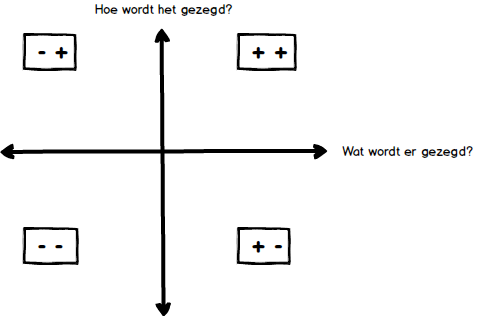 Fig. 3: De 4 mogelijke kwadranten van positief-negatief van wat en hoe. Emotie is een lastig onderzoeksveld om te automatiseren. Emotie kent een algemeen menselijk-deel dat voor alle mensen op aarde bestaat (Geluk, Verdriet, Verrassing, Angst, Weerzin, Boosheid) en als zodanig ook universeel herkenbaar is. Maar er bestaat ook cultuurgebonden emotie. Denk aan humor, sarcasme of ironie. Die zijn in verschillende landen om ons heen al duidelijk anders, dus het is niet zo eenvoudig om deze emoties uit een gesprek te halen.
Fig. 3: De 4 mogelijke kwadranten van positief-negatief van wat en hoe. Emotie is een lastig onderzoeksveld om te automatiseren. Emotie kent een algemeen menselijk-deel dat voor alle mensen op aarde bestaat (Geluk, Verdriet, Verrassing, Angst, Weerzin, Boosheid) en als zodanig ook universeel herkenbaar is. Maar er bestaat ook cultuurgebonden emotie. Denk aan humor, sarcasme of ironie. Die zijn in verschillende landen om ons heen al duidelijk anders, dus het is niet zo eenvoudig om deze emoties uit een gesprek te halen.
Maar wel algemeen is dat emotie altijd een combinatie is van wat er gezegd wordt en hoe dit gezegd wordt. Zo kun je de vreselijkste dingen op een heel vriendelijk manier zeggen en, omgekeerd, ook heel aardige dingen op een boze manier verklanken. Maar meestal zullen het wat en hoe elkaar niet al te veel tegenspreken.
De opnamen
Het leek ons daarom een leuk idee om deze twee facetten van het emotie-onderzoek te laten zien. Iets na 11:00 arriveerden Anne van der Meer (presentatrice/interviewster) en Remco Kikkert (cameraman). Na de koffie, het bekijken van het DesignLab van de UTwente en het voorgesprek waarin we uitlegden wat wel en wat niet kan en hoe je de verschillende onderdelen kunt gebruiken om iets zinnigs over de emotie te zeggen, werd besloten om eerst voor echt materiaal te zorgen. Anne en Arjan zouden een (fake) gesprek voeren waarin Anne boos werd op Arjan (nav een mislukte vakantie). Anne moest daarin zowel “boze” woorden zeggen als zich een steeds bozere “tone of voice” aanmeten.
Het gesprek werd door de spraakherkenner gehaald om erachter te komen welke woorden daadwerkelijk werden gesproken (=herkend). Vervolgens werden die woorden geclassificeerd. Negatieve woorden werden vet en rood gemaakt, positieve woorden vet en blauw. Daarmee kun je in een herkende tekst direct zien hoeveel positieve en hoeveel negatieve woorden erin zitten.
Fig. 4: Automatisch herkende en geannoteerde tekst. De tekst komt uit een (fake) gesprek tussen Anne en Arjan. De speler begint te spelen vanaf het woord waarop geklikt wordt.
Zoals uit figure 4 blijkt, geeft dit al een goed beeld van wat er gezegd wordt. Daarna werd het gesprek door de software van de Twentse PhD-student Jaebok Kim gehaald. Dat programma doet niets met de tekst (=inhoud) maar kijkt puur naar een hele set akoestische parameters. Aan de hand van die parameters besluit het programma de spraak neutraal, positief of juist negatief te labelen.
 Fig. 5: screenshot van de audio-analyse software van Jaebok Kim.
Fig. 5: screenshot van de audio-analyse software van Jaebok Kim.
Dit is dus onafhankelijk van wat er gezegd wordt en alleen gebaseerd op de manier waarop het wordt uitgesproken. De positief-negatief classificaties van de op woord en op spraak-gebaseerde analyse kwamen in dit kleine testje redelijk overeen maar niet helemaal. Het blijft lastig om uit de spraak alleen zoiets te bepalen.
Wel liet het zien dat de combinatie wat en hoe wordt iets gezegd, veel belovend is. We gaan daar zeker mee door!
Wat kun je er nu mee?
 Fig. 6: Anne en Arjan tonen de audio-analyse software in het DesignLab van de UTwente Na dit toneelstukje gingen we naar de grote zaal van het DesignLab in voor het tweede deel: wat kun je er nu precies mee?
Fig. 6: Anne en Arjan tonen de audio-analyse software in het DesignLab van de UTwente Na dit toneelstukje gingen we naar de grote zaal van het DesignLab in voor het tweede deel: wat kun je er nu precies mee?
De HMI-groep van de UTwente is op dit moment bij twee onderzoeken betrokken waarin gekeken wordt naar wat je uit het audiosignaal zou kunnen halen: eentje met het AMC en eentje met het UMC.
AMC
In de groep van Miranda Olff (AMC) wil men weten of een behandeling van PTSS aanslaat. Door de spraak van iemand die voor PTSS behandeld wordt, steeds op dezelfde manier te analyseren, kun je zien of een behandeling effect heeft. Als het goed is, gaat iemand steeds neutraler, uitgebreider en samenhangender over de traumatische gebeurtenis spreken. Dit kunnen we meten door bijvoorbeeld een afname in stopwoorden (“euh”, “zeg maar”), een toename in beschrijvende details en aantal gebruikte woorden, en veranderingen in spreeksnelheid, toonhoogte of trillingen in de stem.
UMC
In de groep van Iris Sommer (UMC) doen ze iets vergelijkbaars. Wij (UTwente) helpen de PhD-studente Janna de Boer met haar onderzoek naar de spraak van jong-volwassenen die een psychose hebben gehad. Een goede psychiater hoort hoe het met zo iemand gaat, maar wat is dat? Is het het woordgebruik, de manier van spreken of een combinatie van deze twee? Ook hier proberen we erachter te komen door te kijken naar “wat” iemand zegt en “hoe” die dat zegt.
In beide onderzoeken is de emotie-detectie via software dus dienend: we proberen allerlei parameters (volume, pauze tussen de woorden, etc.) uit het audiosignaal te halen. Vervolgens bieden we die gegevens aan, in de hoop dat de onderzoekers er iets mee kunnen. Bovendien, in het geval van het UMC-onderzoek, kan de spraakherkenningssoftware gebruikt worden om veel sneller een transcriptie te maken. Normaal kost het 8-uur om 1-uur spraak te transcriberen. Mbv spraakherkenning kan dat teruggebracht worden tot 4 uur.
Afronden opnamen UTwente
Hoewel het uiteindelijke item slechts 2 minuten zou bedragen, waren we nu al ruim 2,5 uur bezig. Cameraman Remco besloot dat het wel aardig zou zijn nog wat sfeerbeelden van het DesignLab te maken. Dat deed ie onder grote belangstelling van de aanwezige studenten en medewerkers die het allemaal reuze interessant vonden.
Telecats
 Fig. 7: Sander en Anne nemen het gesprek nog even door terwijl Remco de camera opstelt. Anne had aangegeven dat ze ook graag bij Telecats langs wilde gaan om te peilen wat een softwarebedrijf nu met “Emotie in Spraakdetectie” zou willen doen. Camera en lampen ingepakt en naar het 1500 meter verderop gelegen Telecats gegaan alwaar Sander Hesselink al stond te wachten.
Fig. 7: Sander en Anne nemen het gesprek nog even door terwijl Remco de camera opstelt. Anne had aangegeven dat ze ook graag bij Telecats langs wilde gaan om te peilen wat een softwarebedrijf nu met “Emotie in Spraakdetectie” zou willen doen. Camera en lampen ingepakt en naar het 1500 meter verderop gelegen Telecats gegaan alwaar Sander Hesselink al stond te wachten.
Besloten werd de opname in de programmeerruimte te maken omdat dat een “levendig” beeld zou schetsen: hier wordt gewerkt.
Bij Telecats wordt spraaktechnologie ontwikkeld voor call centers. Steeds vaker krijgen ze de vraag: “kunnen jullie ook iets zeggen over “emotie” van de beller?”
De-escalatie van 'n gesprek
Een van de zaken waar call centers beducht voor zijn, is het uit de hand lopen van een gesprek. Niemand zit te wachten op een gesprek dat helemaal uit de hand loopt. De medewerker en de beller houden er een naar gevoel aan over en de reputatie van de opdrachtgever wordt er niet beter van. Door nu mee te luisteren en real-time aan te geven of het gesprek goed of juist slecht verloopt kan een supervisor beslissen in te grijpen als hij/zij denkt dat dat verstandig is. Hiervoor ontwikkelde Telecats software die ongeveer werkt met het kwadranten-plaatje hierboven. Herken de gesproken spraak en geef aan wanneer er onwelgevoegelijke woorden gebruikt worden. Analyseer het audiosignaal van zowel de beller als de call center medewerker en geef aan wanneer ze door elkaar gaan spreken en wanneer het volume snel stijgt. Idee hierachter is dat er iets misgaat als mensen elkaar niet meer laten uitspreken (door elkaar spreken) en als ze steeds luider gaan spreken. Gecombineerd met het voorkomen van de verkeerde woorden blijt dit een redelijk goede voorspeller te zijn voor het uit de hand lopen van een gesprek.
Zijn onze bellers tevreden?
Het tweede doel waarvoor EiS kan worden ingezet is het analyseren van grote hoeveelheden gesprekken. Opdrachtgevers willen graag weten of “men” over het algemeen wel/niet tevreden is. Stel nu dat je alle gesprekken door de herkenner haalt waardoor je weet wat er gezegd werd. Je kunt dan bepalen welke positieve/negatieve woorden gebruikt werden. Door ook naar de andere parameters te kijken (volume en door elkaar praten) kun je over al die gesprekken een soort waardeoordeel geven: in X% van de gesprekken praat men door elkaar en in Y% worden veel “negatieve” woorden gebruikt. Door dit om de zoveel tijd opnieuw te doen, kan een goed beeld verkregen worden van het verloop van de gesprekken.
Filmpje maken
Na het interview met Sander waren de opnames gemaakt (20 min materiaal) en moest Anne aan de slag om er een “verhaaltje” van ong. 2 minuten van te maken. Normaal wordt dat in de studio in Amsterdam gedaan, maar daar was het te laat voor. Telecats had nog een kamer over en de volgende 2 uur besteedde Anne aan het monteren van de uitzending. Remco was klaar en vertrok terug naar Groningen.
Tegen 5 uur was ook Anne klaar en werd alles naar de RTL-server gestuurd. We mochten (begrijpelijkerwijs) geen kopie van het materiaal maken, maar wel alvast het filmpje bekijken.
Ondank het feit dat ik een hekel heb aan het terug zien en luisteren van mijzelf, viel het allemaal niet tegen: het was een mooi verhaal geworden. En na wat nababbelen ging iedereen terug naar huis (het was tenslotte vrijdagmiddag 16:30).
De uitzending
Op verschillende plekken in Nederland zaten om 18:15 mensen gespannen naar Editie-NL te kijken: wanneer komt het nu? En, daar was het, maar….. er was niet de hele tijd geluid? Het filmpje bestond uit een deel met de camera opgenomen geluid (gesprekken) en een deel filmpje (het fake interview). Het geluid van dat filmpje was men vergeten te selecteren dus iedere keer als daar wat van werd getoond, viel het geluid weg. Na 15 sec besloot de eindredactie van Editie-NL er de stekker uit te halen. Balen!! Maar als het goed is, wordt komende week de uitzending alsnog vertoond.
Al-met-al een leuke dag met een wat teleurstellende afloop.
Uiteindelijk
Na een week zenuwachtig wachten (zou het er nog van komen?) kwam de verlossen de WhatsApp: vrijdagavond 18:15!
Filmpje bleek uiteindelijk helemaal niet onaardig hoewel de aankondiging van de presentatoren (software spoort depressies op) helemaal nergens op sloeg. Maar goed, zo gaan die dingen.
Na de uizending konden we vrij eenvoudig het filmpje downloaden, door de spraakherkenner halen en op de site zette: met behoorlijk goede ondertiteling. Hieronder weer de twee varianten: het TV-programma met ondertiteling en de Karaoke-versie met meelopende tekst.
{tab=Ondertiteling}
{tab=Karaoke}