
Achtergrond
Al sinds de eerste jaren van het internet, bestond er de behoefte om te kunnen zoeken in de content die datzelfde internet ontsloot. Ging het in eerste instantie nog met specifieke zoektechnieken zoals Boolean Search, later kwamen er meer verfijnde technieken die over het algemeen beter aansloten bij de manier waarop mensen gewend waren te zoeken.
 De antwoorden op een zoekvraag waren en eigenlijk zijn nog steeds vrij simpel: hier heb je een lijst met verwijzingen (links naar andere website, naar documenten, video’s, etc) waarin volgens ons zoekalgoritme het juiste antwoord hopelijk staat. Succes ermee!
De antwoorden op een zoekvraag waren en eigenlijk zijn nog steeds vrij simpel: hier heb je een lijst met verwijzingen (links naar andere website, naar documenten, video’s, etc) waarin volgens ons zoekalgoritme het juiste antwoord hopelijk staat. Succes ermee!
Dit is lang niet altijd verkeerd. Wil ik iets weten over “Karel en de Elegast” dan is er niets mis mee dat ik een lijst met verschillende verwijzingen naar informatie over dit heldenepos krijg. Ik kan die bekijken en zelf beslissen welke documenten ik hierover wil lezen of bekijken.
Anders ligt het wanneer ik wil weten wat “Karel en de Elegast” is. Dan wil ik een kort antwoord: “een heldenepos uit 1270 over de avonturen van Keizer Karel de Grote (748-814)”.
De eerste manier van zoeken-vinden is, zeker sinds de komst van Google, enorm uitgebreid en goed en wordt niet-voor-niets dagelijks door honderdduizenden Nederlanders gebruikt. De tweede, waarbij je een antwoord wilt hebben op een gestelde vraag (en dus niet: hier kun je het antwoord waarschijnlijk zelf vinden), is veel minder goed ontwikkeld. Met de komst van Linked (Open) Data, RDF, Wikipedia en vooral DBpedia is daar veel in verbeterd. Zoek je nu naar bv Telecats, dan krijg je links nog steeds de lijst met wellicht relevante documenten, maar aan de rechterkant krijg je een soort antwoord in de vorm van wat plaatjes van het gebouw, de sluitingstijden (wij schijnen al om 17:30 te stoppen met werken) en een plattegrond van de omgeving.
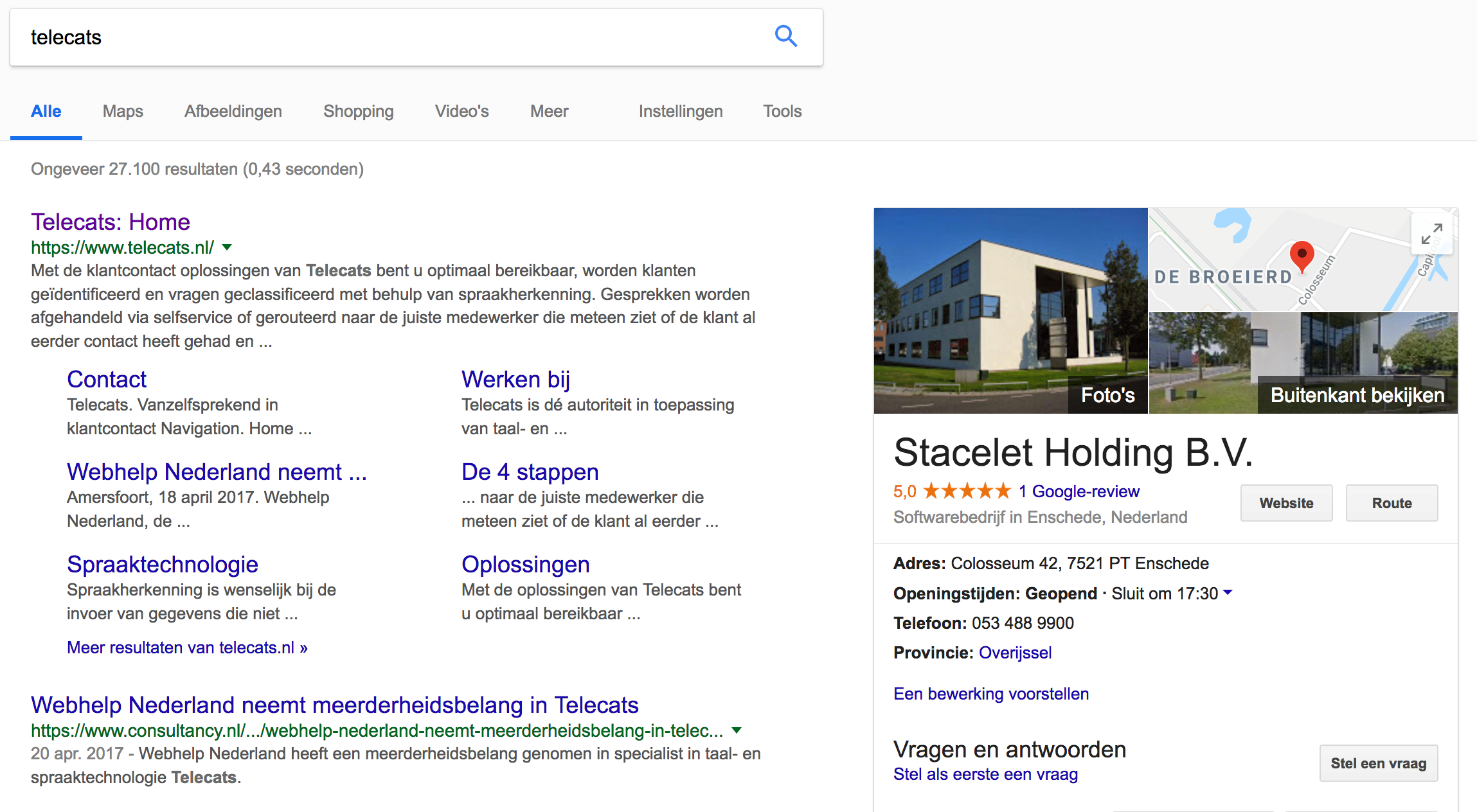 Antwoord op de zoekvraag "wat is Telecats".
Antwoord op de zoekvraag "wat is Telecats".
Het antwoord wordt gegeven via een aantal voor bedrijven relevante gegevens zoals openingstijden, locatie, eigenaren en meer.
Dit is een mooie ontwikkeling en zal ervoor zorgen dat het internet steeds meer ook een soort vraag-antwoord karakter zal krijgen. Maar dit geldt voor de informatie die “publiek” ontsloten is en waar zoekmachines dus makkelijk bij kunnen. Bovendien is het zo dat Google (en andere zoek engines zoals BING - Microsoft) bepalen welk antwoord jij gaat krijgen.
Zoals de affaire rond Facebook - Cambridge Analytics heeft laten zien, is het zeker niet zo dat de gegeven antwoorden “waarde vrij” zullen zijn. Het antwoord kan afhangen van de computer die je gebruikt, eerdere zoekvragen, je IP-adres, etc. Bovendien is het zo dat eigenaren van de content slechts in zeer beperkte mate invloed hebben op de antwoorden die gegeven worden.
Gaan we bij Google zoeken naar hoe zet ik een Billy in elkaar dan krijg ik als eerste antwoord een YouTube-filmpje, dan een aantal verwijzingen naar handleiding.com en op de vijfde plek een soort scheldkanonnade.
 Een wat overtrokken en onterecht antwoord maar door de vraag-antwoorden “uit te besteden” aan internet, is IKEA hier bijna alle controle kwijt.
Een wat overtrokken en onterecht antwoord maar door de vraag-antwoorden “uit te besteden” aan internet, is IKEA hier bijna alle controle kwijt.
Zoeken in de eigen content
Om hier iets aan te doen, moet een leverancier het mogelijk maken om bijvoorbeeld via de eigen website alleen in de, door de leverancier goedgekeurde informatie te zoeken. Dat kan ook m.b.v. Google maar dan krijg je weer die lijst met mogelijke documenten/links waarin je zelf de informatie moet opzoeken.
Chatbots
Joseph Weizenbaum's Eliza kan gezien worden als “De moeder van alle Chatbots”. Eliza werd geprogrammeerd om trefwoorden te matchen met een dataset in een gesloten domein. De meest populaire versie van Eliza lag op het gebied van de Rogeriaanse psychotherapie.
Q: ik voel me ongelukkig
A: wat vind jij daar zelf van?
Etc.
Om echt antwoord te geven op gestelde vragen werd in de jaren negentig een soort vraag-antwoord programma bedacht dat in 1994 bekend werd als Chatbot. Aanvankelijk werden gestelde vragen bijna geheel handmatig aan antwoorden gekoppeld: werkte goed, zolang de vragen maar leken op de voorbeeldvragen. Naarmate de taaltechnologie beter werd, werd het scala aan te beantwoorde vragen groter. Zo kon je vragen als “ik wil mijn abonnement opzeggen” en “hierbij zeg ik mijn abonnement op” aan elkaar gelijkstellen en daar een antwoord op geven.
En hoewel deze techniek zeer bruikbaar was, bleek al snel dat meer ingewikkelde vragen hiermee niet beantwoord konden worden. Ook ontkenningen (“ik wil mijn abonnement niet opzeggen, maar…”) zorgde voor veel problemen. Machine Learning waarbij niet alleen gekeken werd naar de woorden die wel in de vraag voorkwamen maar ook naar woorden die juist niet voorkwamen, bleek een uitkomst waardoor de chatbot-technologie weer een flink stuk robuuster werd. Wel werd het steeds meer duidelijk dat we voor deze technologie grote hoeveelheden beoordeelde data nodig hadden.
M.a.w. je hebt duizenden voorbeelden nodig van door mensen gemaakte vraag-antwoord paren. De komst van geavanceerdere zelflerende systemen (o.a. Deep Neural Networks) en grote hoeveelheden data, maakte het mogelijk de chatbot-technologie steeds beter te maken.
Avatars
De eerste vraag-antwoord applicaties bestonden allemaal uit een invoerregel en een submit-knop. In een tekstveld daaronder verscheen dan het antwoord. Al snel werd geprobeerd dit wat aantrekkelijker te maken door er een plaatje van een (meestal een mooi) meisje bij te zetten.
![]() De volgende stap was een meer geavanceerde avatar die de antwoorden min-of-meer lip-synchroon uitsprak. Voor het voorlezen van het antwoord wordt danText-to-Speech gebruikt; een technologie die zo goed wordt dat het, bij korte antwoorden, nauwelijks meer van echt te onderscheiden is.
De volgende stap was een meer geavanceerde avatar die de antwoorden min-of-meer lip-synchroon uitsprak. Voor het voorlezen van het antwoord wordt danText-to-Speech gebruikt; een technologie die zo goed wordt dat het, bij korte antwoorden, nauwelijks meer van echt te onderscheiden is.
Toch zette deze trend van “namaak-mensen” niet echt door en gebruiken de meeste chatbots tegenwoordig een meer karikaturale avatar of slechts een plaatje met een tekstueel antwoord. De mensachtige avatars voegden weinig nut toe maar kosten wel veel overhead voor het animeren.
Gesproken chatbots
Naarmate de spraakherkenning beter werd, werd steeds vaker geëxperimenteerd met gesproken chatbots waarbij zowel de vraag als het antwoord via spraak gingen. Ideaal voor situaties waarbij je je handen nodig hebt of waarbij het verboden is om het toestel aan te raken (mobiele telefoon in de auto). Een van de bekendste voorbeelden is natuurlijk TomTom waarbij je het adres volgens een vast stramien (stad, straat, huisnummer) kon inspreken, waarna het kastje je zo snel mogelijk naar het juiste adres leidde.
De grote doorbraak kwam met het verschijnen van SIRI voor iOS (2011). Aanvankelijk alleen voor het Engels, maar later ook voor andere talen. SIRI was toentertijd erg revolutionair en er werd enorm veel van verwacht. Er verschenen talloze filmpjes waarin mensen vroegen of ze een paraplu moesten meenemen, of SIRI de kookwekker op 3 minuten kon zetten of dat SIRI iemand op z’n mobiele nummer wilde bellen. Later kwamen daar ook “Location Based Services” bij waarbij je kon vragen of er een goed Italiaans restaurant in de buurt was. Het initiatief van Apple werd snel gekopieerd door Google (Google Now, 2012) en Microsoft (Coratana, 2013).
En hoewel de spraakherkenning bijna vlekkeloos werkt, werd snel duidelijk dat het succes van dit soort Avatars afhang van de aanwezigheid van “context informatie”. Ook al herkent de app perfect de ingesproken zin “wat is de dichtstbijzijnde Volvo-garage”, zolang de app niet weet wat een Volvo-garage is en als ie het wel weet, waar die garage dan is, heb je er weinig aan. Meestal volstaat SIRI met het vertalen in tekst van de ingesproken vraag om die vraag dan op internet te zetten. Je krijgt dan weer een lijst met Volvo-garages terug.
Google deed het al snel beter. Niet omdat de spraakherkenning beter was, maar omdat Google veel meer informatie had (heeft) en dus veel beter een juist antwoord kan componeren. Apple heeft op dit vlak duidelijk haar aanvankelijke voorsprong verspeeld.
Praatpalen
 De grote doorbraak kwam in 2014 met de praatpaal van Amazon: Alexa. De goede spraakherkening, de open structuur (veel API’s beschikbaar) en de makkelijke bediening werd Alexa snel zeer populair en dus gekopieerd door Google (Google Home. 2016).
De grote doorbraak kwam in 2014 met de praatpaal van Amazon: Alexa. De goede spraakherkening, de open structuur (veel API’s beschikbaar) en de makkelijke bediening werd Alexa snel zeer populair en dus gekopieerd door Google (Google Home. 2016).
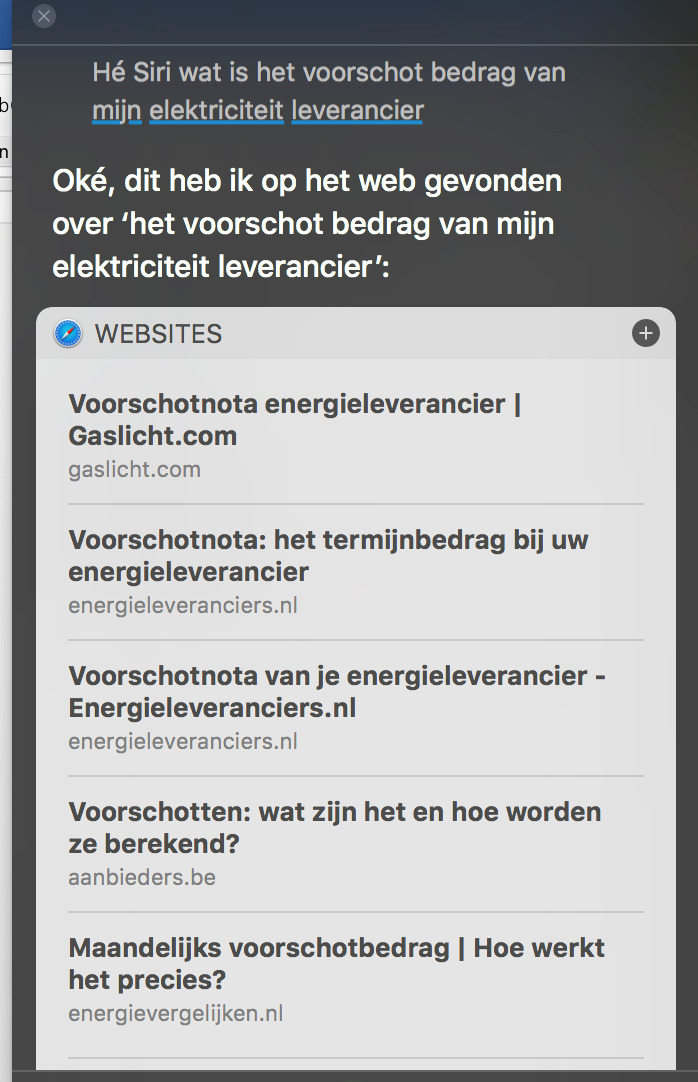
Met beide praatpalen kun je je huis automatiseren (lichten aan/uit doen, de voordeur openen/op slot doen, je favoriete speellijst afspelen en nog veel meer. Het is dan ook te verwachtten dat dit soort praatpalen de rol van chatbots voor een deel gaan overnemen. I.p.v. je energieleverancier te bellen met een vraag over je voorschotbedrag, stel je die vraag straks aan Alexa/Google Home/Coratana/SIRI (zie hiernaast).
Als die praatpaal dan jouw informatie heeft, kan die contact leggen met jouw energieleverancier om te achterhalen wat jouw voorschotbedrag is.
Maar ook hier geldt het eerder genoemde bezwaar: de content-eigenaar is hier niet volledig de baas over de dialoog. Opnieuw zijn het de grote Amerikaanse Techgiganten die “eigenaar” zijn over “jouw” vraag-antwoord applicatie.
Gesproken Chatbots
Naarmate de spraakherkenning beter wordt, wordt de vraag om volledig gesproken chatbots op de eigen website steeds groter. Je zou denken dat, als je eenmaal een tekstuele chatbot hebt, het eenvoudig moet zijn om hem voor spraak geschikt te maken. Het antwoord hierop is ja en nee. De structuur van de dialoog kan eenvoudig hergebruikt worden en de tekstuele invoer vervangen door de resultaten van de spraakherkenner. Het antwoord geef je dan via Tekst-to-Speech en klaar is kees. Maar….. zo eenvoudig is het niet.
Ten eerste is het niet zeker dat het soort vragen dat je via spraak stelt gelijk is aan de vragen die je via tekst stelt. In 2010 hebben we dat bij Telecats eens uitgezocht voor FAQ’s. Toen bleek dat men andere soort vragen stelde via de web-interface (tekst) dan via de telefoon (spraak). Als je andere soort vragen krijgt, moet het systeem dus opnieuw worden getraind.
Ten tweede is het zo dat bij tekst-invoer je typo’s kunt maken, terwijl je bij spraak-invoer juist verkeerde woorden herkent (maar wel goed geschreven).
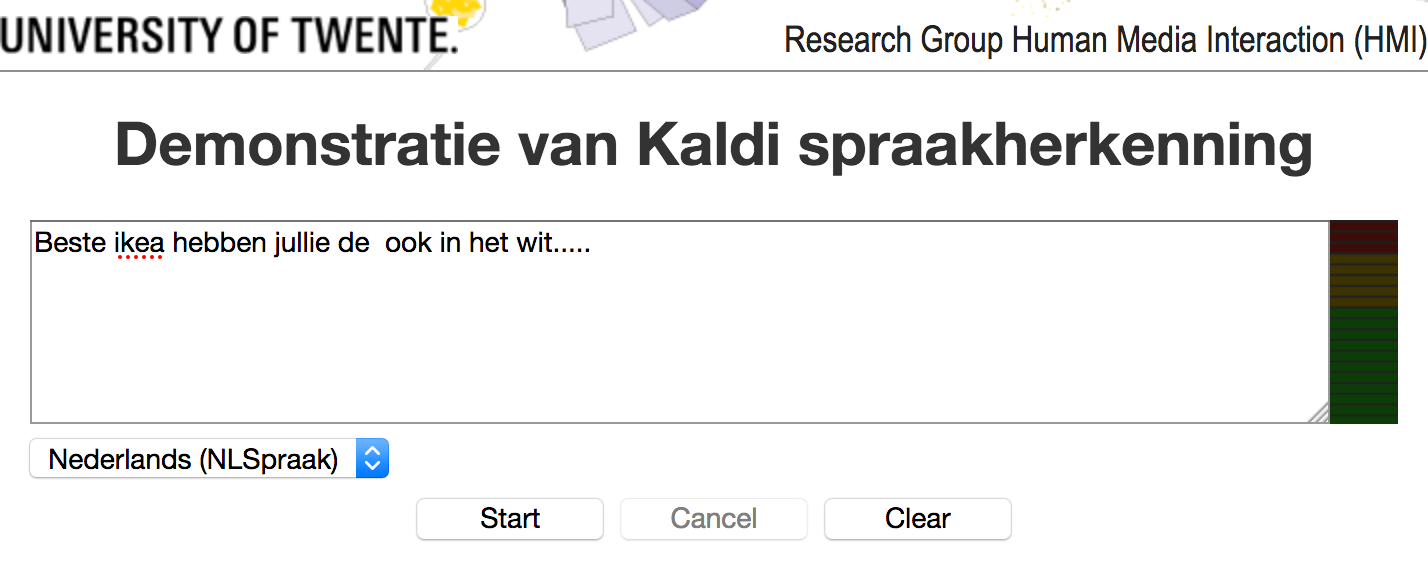 Website van de Spraakherkenner van de Universiteit Twente.
Website van de Spraakherkenner van de Universiteit Twente.
Een mooie mogelijkheid om eens zelf uit te testen hoe goed spraakherkenning voor jouw stem werkt.
Ten derde is het zo dat bij content-specifieke dialogen je dikwijls allemaal eigennamen en/of woorden in een andere taal dan Nederlands hebt. Stel je wilt bij dat leuke restaurant in de stad een aantal dingen om te eten bestellen. De algemene spraakherkenning gaat goed, maar de woorden “Assiette” “Clarenteries” of “Veau” worden gewoon niet herkend omdat a) ze anders worden uitgsproken dan dat de Nederlandse klankregels voorspellen, en b) de meeste Nederlanders ook niet weten hoe uitgesproken moeten worden en dus maar wat doen.
 Menubord in het Frans van een Nederlandse Bistro.
Menubord in het Frans van een Nederlandse Bistro.
Hoe leest een gemiddelde Nederlander dit voor?
De spraakherkenner geeft dan (intern, niet zichtbaar op het scherm) een <unk> (=unknown word). En nu zijn dit nog geeneens de lastigste voorbeelden?
Tenslotte is er de feedback. Bij veel succesvolle gesproken chatbots zie je wat je inspreekt direct op het scherm. Is de herkening verkeerd of heb je iets verkeerd ingesproken, dan zie je dat direct op het scherm (denk aan de gesproken invoer bij TomTom). Als het dan verkeerd gaat, dan weet je direct dat dat komt door of de herkenner of door jou. Je kunt de invoer dan makkelijk overrulen door het opnieuw in te spreken. Als je geen visuele feedback hebt (aan de telefoon) dan zul je er vanuit gaan dat bij verkeerde antwoorden het systeem gewoon niet werkt. Maar dat weet je pas als het verkeerd gaat.
Door deze vier “bezwaren” is het maken van een gesproken chat een stuk lastiger dan men dikwijls denkt en een eenvoudige copy-paste is helaas niet de aangewezen weg.
Toekomst
Is het gebruik van gesproken chatbots uitgesloten? Nee, dat niet maar we hebben hierboven (hopelijk) duidelijk gemaakt dat er best wel wat bij komt kijken en je dus niet direct een bestaande tekstuele chatbot kunt overzetten naar een gesproken versie. Met het (nog steeds) beter worden van de spraakherkenning en goede gesproken feedback is het zeker mogelijk om goede, gebruiksvriendelijke gesproken chatbots te maken zoals het overweldigende succes van Amazon’s Alexa laat zien. Het is alleen niet zo dat een werkende tekstuele chatbot makkelijk overgezet kan worden in een gesproken variant.
Arjan van Hessen