
Achtergrond
 In 2017 werden we uitgenodigd door het DITSS Veiligheidsatelier om bijgepraat te worden over mogelijke projecten. Een van de projecten ging over het veiliger maken van een kruispunt, een ander over het "sneller en juist duiden van 112-alarmmeldingen bij de politie".
In 2017 werden we uitgenodigd door het DITSS Veiligheidsatelier om bijgepraat te worden over mogelijke projecten. Een van de projecten ging over het veiliger maken van een kruispunt, een ander over het "sneller en juist duiden van 112-alarmmeldingen bij de politie".
Vraag
Het operationeel centrum van de nationale politie wil meldingen van spraakoproepen, beelden en video’s sneller duiden om eerder de juiste hulp te kunnen verlenen. Zij zijn op zoek naar een technologische oplossing, die de medewerker van het politie operationeel centrum assisteert, in het destilleren van de melding om daarmee sneller te weten te komen wat er aan de hand is en sneller te determineren welke vervolgactie nodig is. Daarbij denkt de politie in eerste instantie in onderzoeken of oplossingen voor spraakoproepen in diverse dialecten en straattalen. Deze technologische oplossing zou automatisch uit een gesproken alarmmelding delict gegevens dienen te identificeren; o.a. locatie, soort, urgentie, wapen, dader omschrijving en meer. De Nationale politie stelt een bedrag beschikbaar voor een goed voorstel tot verder onderzoek of een (gedeelte van) oplossing en deze te bewijzen in een fieldlab.
Gaaf, leek me precies iets voor een academische-commerciele samenwerking.
Wij (=Telecats) zijn aan tafel gaan zitten met de Radboud Universiteit en een, uit de politie voortkomende, start-up: Pandora Intelligence. Na enige brainstormsessie bleek dat de Politie veronderstelde dat wij alles zouden gaan trainen en showen op basis van de bestaande 112-opnamen. Dat was nl makkelijk ivm de privacy. We hebben een aantal van die opnamen beluisterd en kwamen snel tot de conclusie dat dat niet ging werken. Door de hoge kosten in het verleden van opslag, waren alle geluidsopnamenzwaar gecomprimeerd en in mono opgelsagen. De geluidskwaliteit was bagger en het hardere geluid van de 112-medewerkers overstemde dikwijls dat van de beller. Kortom: hier hadden we niks aan.
Doel
 Deels herkende nummerbord leidt tot identificatie van voertuig en eigenaar door koppeling met de RDW Om aan de wensen van de Politie te kunnen voldoen, moesten we de spraak van zowel de beller als de 112-medewerker herkennen, interpreteren en actie ondernemen. Stel iemand zegt “ik zie een zwarte stationcar met kenteken 26-LZ- en nog iets, dan kan de politie direct een lijntje leggen naar de RDW en dar alle zwarte stationcars opvragen die 26-LZ in het nummerbord hebben staan. Als vervolgens de auto geidentificeerd is, kan de eigenaar opgevraagd worden etc. etc. Ook plaatsnamen kunnen direct gebruikt worden. Als herkend wordt “ik sta hier op de Maliebaan” dan kan via in GoogleMaps direct de Maliebaan getoond worden. Doordat bij 112-gesprekken de locatie van de beller enigszins bekend is, hoeft niet nader gevraagd te worden om welke Maliebaan het eigenlijk gaat. Op deze manier kan de 112-medewerker tijdens het gesprek al extra informatie voorgeschoteld krijgen die hij/zij slechts hoeft te bevestigen ipv in te voeren.
Deels herkende nummerbord leidt tot identificatie van voertuig en eigenaar door koppeling met de RDW Om aan de wensen van de Politie te kunnen voldoen, moesten we de spraak van zowel de beller als de 112-medewerker herkennen, interpreteren en actie ondernemen. Stel iemand zegt “ik zie een zwarte stationcar met kenteken 26-LZ- en nog iets, dan kan de politie direct een lijntje leggen naar de RDW en dar alle zwarte stationcars opvragen die 26-LZ in het nummerbord hebben staan. Als vervolgens de auto geidentificeerd is, kan de eigenaar opgevraagd worden etc. etc. Ook plaatsnamen kunnen direct gebruikt worden. Als herkend wordt “ik sta hier op de Maliebaan” dan kan via in GoogleMaps direct de Maliebaan getoond worden. Doordat bij 112-gesprekken de locatie van de beller enigszins bekend is, hoeft niet nader gevraagd te worden om welke Maliebaan het eigenlijk gaat. Op deze manier kan de 112-medewerker tijdens het gesprek al extra informatie voorgeschoteld krijgen die hij/zij slechts hoeft te bevestigen ipv in te voeren.
 Google Maps afbeelding van de Utrechtse Maliebaan wordt getoond als "ik sta op de Maliebaan" herkend wordt.
Google Maps afbeelding van de Utrechtse Maliebaan wordt getoond als "ik sta op de Maliebaan" herkend wordt.
Maar om te weten hoe goed de spraakherkennin (ASR: Automatic Speech Recognition) en hoe goed de duiding van de woorden (NER: Named Entity Recognition) moet zijn, moest er een Ground Truth worden bepaald: een door deskundige mensen bepaalde waarheid die vergeleken kon worden met de resultaten van ASR en NER. Pas als bleek dat ASR en NER voldoende goed werken, kon de volgende stap worden genomen: iets doen met deze informatie.
Database
We hebben daarom besloten het anders aan te pakken en eerst een database met 45 uur gevalideerde, kwalitatief hoge kwaliteit spraak op te nemen, deze data verbatim uit te schrijven en van alle woorden de part-of-speech en eventueel de Named Entity te bepalen.
Om dit te realiseren, hebben we samen met KPN een "afluisterdoos" in de 112-centrale gezet en daar, netjes verspreid over locatie en tijd, ongeveer 65 uur spraak op genomen in hoge kwaliteit en stereo. Uit deze 65 uur is een selectie van 45 gemaakt die door studenten van de Radboud Universiteit volledig werden getranscribeerd en benoemd. Voor een uur spraak ben je dan ongeveer 16 uur bezig zodat de totale 45-uur op ≈750 uur uitwerken neerkomt. Het transcriberen van 112-gesprekken is niet alleen inspannend maar bovendien geestelijk behoorlijk zwaar. Om de toch wel jonge studenten te beschermen, werden de ergste gesprekken er door 112-medewerkers uitgehaald. Bovendien liep er een psycholoog mee om het geheel in de gaten te houden!
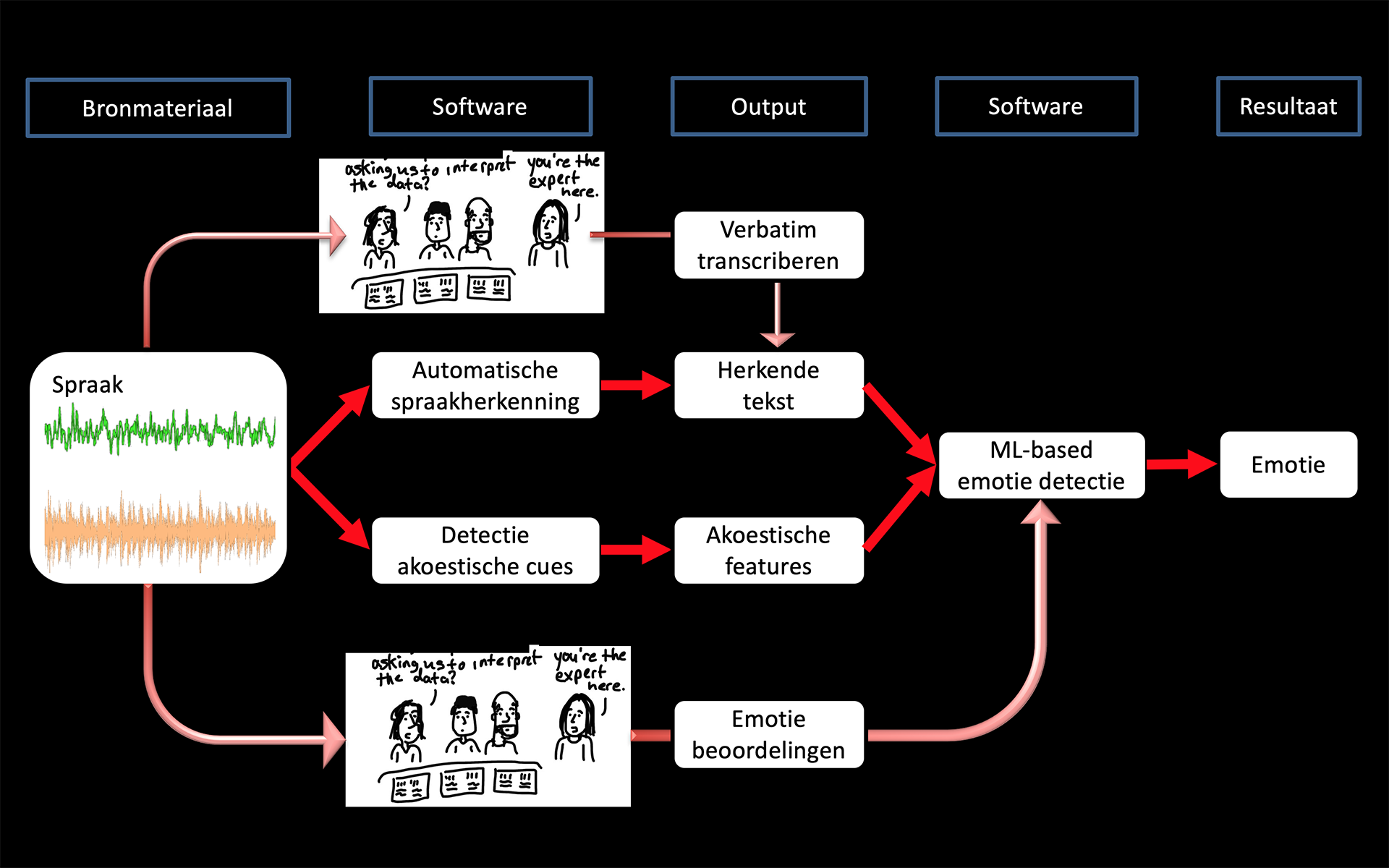 Transcriptie schema van het project en de plek waar de geautomatiseerde processen tzt een rol gaan spelen.
Transcriptie schema van het project en de plek waar de geautomatiseerde processen tzt een rol gaan spelen.
Deze database zou dan van de politie worden en die kon dan zelf bepalen wie de volgende stap zou mogen doen: het herkennen en van de spraak en het benomen van de woorden.
Natuurlijk hopen we dat wij dat weer zullen zijn, maar zeker is het niet.
Het voordeel van deze aanpak is dat de politie een goede set data heeft waar ze zelf en in samenwerking met derden mee aan de slag kunnen.
Droom
Onze droom wordt redelijk gevisualiseerd door een fraai mock-up filmpje van Pandora.
"Een in Nederland verblijvende Engelsman belt de 112-centrale ivm een inbraak en gijzeling/ontvoering van zijn vrouw." De tekst van de beller wordt herkend en de Named Entities benoemd. Eventuele acties worden als suggestie op het scherm getoond en de 112-medewerker hoeft die suggesties alleen maar te bevestigen (stuur een ambulance, stuur gewapende eenheid, etc.). De op deze manier uit het spraaksignaal verkregen informatie wordt verrijkt middels koppelingen met open en besloten databases (Kadaster, RDW, Social Media, etc.).
Op deze manier ontstaat een rijk beeld van de gebeurtenis die door de regiekamer (dat zijn de mensen die de uiteindelijke beslissingen nemen) beter geïnterpreteerd kunnen worden dan dikwijls nu het geval is.
Hoever zijn we nu?
Op dit moment (begin oktober 2018) hebben we de opnamen gemaakt (65 uur) en de beloofde 45 uur getranscribeerd. De komende maanden gaan we zien hoe goed we de spraak en de entiteiten kunnen herkennen. Ondertussen kan Pandora aan de slag om op basis van de perfecte data de intelligentie er aan toe te voegen.