
Dankzij kunstmatige intelligentie zijn de resultaten van automatische spraakherkenning flink verbeterd. Steeds meer Oral History-onderzoekers maken er gebruik van.
Erica Renckens
Dit artikel is een uitgebreidere versie van het stuk dat in de oktober uitgave van eData&Research staat.
Automatische spraakherkenning (ASR) bestaat inmiddels al een tijdje, maar de resultaten lieten tot voor kort nogal wat te wensen over: zeker wanneer het gaat over normale, menselijk spraak in alledaagse omstandigheden met hier en daar wat achtergrondlawaai. In akoestisch stille ruimten en getraind op één gebruiker ging het nog vrij aardig, maar algemene software kon vaak weinig chocola maken van een audiosignaal. De lage kwaliteit van de spraakherkenners maakte het analyseren en doorzoeken van spraakopnames erg lastig. Met de komst van Deep Neural Networks (DNN) en het gebruik ervan voor spraakherkenning (Microsoft, Interspeech 2010, Firenze) veranderde dat. Al snel volgde de rest van de wereld en tegenwoordig is er eigenlijk geen spraakherkenner meer die deze technologie niet gebruikt. Al snel na de eerste DNN-successen, besloten een aantal enthousiaste spraaktechnologen een open source toolkit te maken waarmee iedereen (en dus ook diegene zonder gedegen kennis van neural networks) een DNN-gebaseerde herkenner konden maken. Dit was Kaldi: een gratis open-source toolkit, die door iedereen gebruikt kan worden en waarmee iedere taal (mits men voldoende geschikte audio-data heeft) een eigen spraakherkenner kan maken.
'Kaldi werkt onder andere met Deep Neural Networks (DNN), die een veel beter akoestisch model genereren dan de “klassieke” modellen die nog met “Gausian Mixture Modellen” werkten, legt Arjan van Hessen, spraaktechnoloog aan de Universiteit Utrecht en de Universiteit Twente, uit. De Universiteit Twente en het Nederlands Instituut voor Beeld en Geluid hebben op basis van Kaldi een nieuwe, open source spraakherkenner voor het Nederlands ontwikkeld die momenteel door de nationale Politie en de FIOD getest wordt. In samenwerking met het CLST van de Radboud Universiteit en CLARIN-EU wordt deze herkenner verwerkt in een zgn Transcription Chain: een workflow die (Oral History-) onderzoekers de mogelijkheid biedt hun eigen opnamen (meestal interviews) te digitaliseren, te transcriberen en/of op te lijnen, te corrigeren en van relevante metadata te voorzien. Het resultaat van de spraakherkenner cq oplijner is een reeks woorden waarvan op de milliseconde bekend is wanneer ze werden uitgesproken.
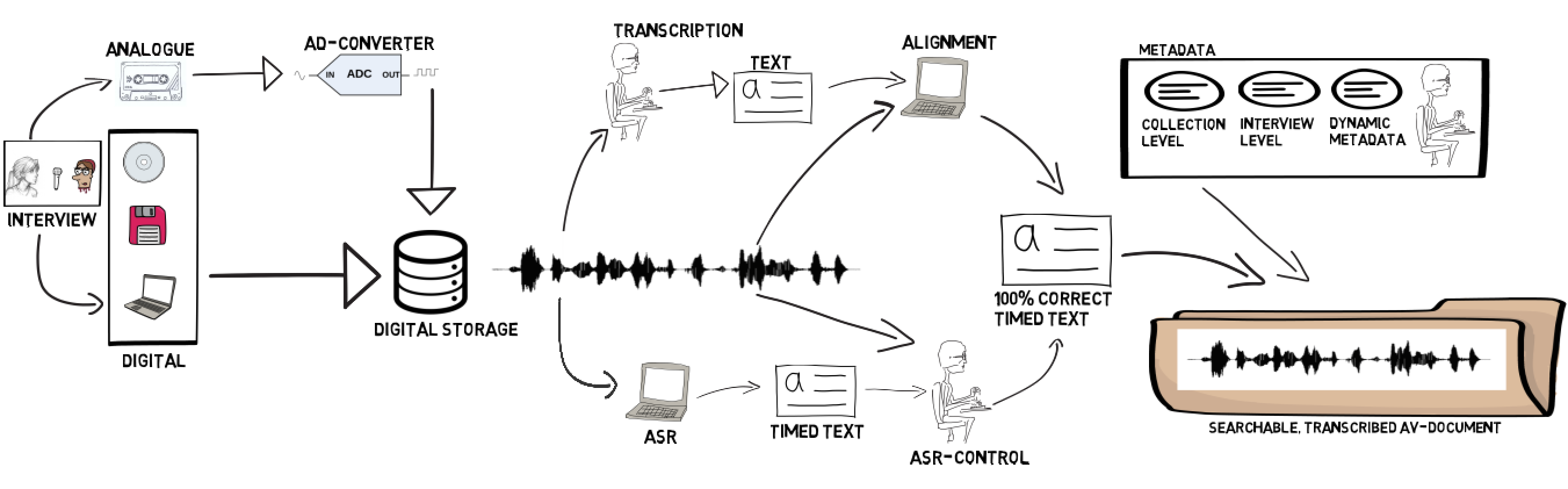 Geluidsopname
Geluidsopname
'Als de omstandigheden optimaal zijn (mooie, schone geluidsopnamen, heldere wijze van spreken met volzinnen ipv gestamel, geen of weinig jargon-woorden), is 90% a 95% van de herkende tekst correct waarbij “wasmachine reparateur” (moet eigenlijk “wasmachinereparateur” zijn) als goed gerkend wordt. Door de goede resultaten zien we, aldus Van Hessen, een sterk toenemende vraag naar spraakherkenning, waarbij de herkenningsresultaten gebruikt worden om a) sneller een verslag te maken en b) te kunnen zoeken in de opnamen.
Veel gebruikers hebben echter geen idee hoe een goede opname te maken. Dikwijls legt men de smartphone gewoon op tafel waardoor ieder contactgeluid (meetypen, schuiven van kopjes, op tafel tikken met de nagels) keihard door de opname heenkomen. Gebruik van een kussentje of desnoods de beschermhoed van de laptop doet hier al wonderen.
Ook realiseren veel interviewers zich niet dat backchanneling (het verbaal ondersteunen van de geinterviewde: ja ja, duidelijk, ga door etc.) voor mensen geen enkel probleem oplevert: wij horen hier doorheen en filteren het weg, maar dat het voor de herkenner vooralsnog lastig is het onderscheid te maken. Bij dat soort opnamen zie je dus dikwjils allerlei “ja ja’s” door de tekst lopen en dat verhoogt de leesbaarheid beslist niet. Door gebruik van bv handgebaren kan de kwaliteit van de opname en dus de uiteindelijke herkenning, echter makkelijk sterk verbeterd worden.
Taalmodel
Het resultaat van de spraakherkenning hangt niet alleen af van de kwaliteit van de opname. ‘Het taalmodel (een statistisch model dat voorspelt wat de kans is op woord X gegeven de woorden Y en Z) moet zo goed mogelijk aansluiten bij het onderwerp van het gesprek’, aldus Van Hessen. Het woordgebruik in een interview met iemand die vertelt over zijn tijd in Buchenwald zal beslist andere woorden en woord-combinaties kennen dan een gesprek over de kredietcrisis of over de klimaatverandering. In het ideale geval gebruik je hier dus drie verschillende taalmodellen, maar in de praktijk is dat niet zo. Het maken van een apart taalmodel is nu nog te arbeidsintensief. Wel zijn we hard aan het werk om gebruikers de mogelijkheid te bieden zelf een woordenlijst toe te voegen.
Later dit jaar hoopt het team de Transcription Chain verder uit te breiden met een editor waarmee de output van de spraakherkenner eenvoudig gecorrigeerd kan worden. ‘Daar heb je wel al toepassingen voor, maar die zijn niet altijd gebruiksvriendelijk. Natuurlijk kun je de tekst in een teksteditor gewoon aanpassen, maar dan gaat de tijdinformatie verloren waardoor oplijnen en zoeken in het geluidsignaal niet meer mogelijk is.’
Stijgend gebruik
Van Hessen ziet het gebruik van ASR bij de overheid (Tweede Kamer, provincies, gemeenteraad, politie, FIOD) de laatste tijd sterk toenemen. ‘Ook onderzoekers die gebruikmaken van gesproken getuigenissen ontdekken steeds meer het gemak ervan en storen zich niet meer zo erg aan de gemaakte fouten. Met de beoogde workflow zal dit hopelijk nog verder toenemen.’
Meer informatie over de Transcription Chain: http://oralhistory.eu/workshops/transcription-chain