
by Stef Scagliola.
This blog already appeared on the website of C2DH
 Sogno di Costantino di Piero della Francesca. It is the first fresco with a "notturno": a "night scene" with light and shadows. The challenge of this workshop on 'transcription and technology’, which took place from 10 to 12 May in Arezzo (IT), consisted in turning recorded human speech into a textual representation that is as close as possible to what has been uttered.
Sogno di Costantino di Piero della Francesca. It is the first fresco with a "notturno": a "night scene" with light and shadows. The challenge of this workshop on 'transcription and technology’, which took place from 10 to 12 May in Arezzo (IT), consisted in turning recorded human speech into a textual representation that is as close as possible to what has been uttered.
Say Arezzo and any art historian’s thoughts will divert to Piero della Francesca’s innovation in the visual representation of reality. It was this renaissance painter of the 15th century who in his frescos dared to depicture religious figures as real humans. By creating the illusion of depth and light and by paying detailed attention to the anatomy of their bodies, Christ, the Madonna and other holy personalities were no longer spiritual creatures floating in the air, but looked like real people.
Goal of the workshop
The efforts of a workshop on 'transcription and technology’, which we attended from 10 to 12 May in this beautiful Tuscan town, were also geared towards an accurate representation of reality. The main goal of the workshop was to come forward with a proposal for a Transcription Chain. A set of web-based services turning recorded human speech into a textual representation that is as close as possible to what has been uttered.
Speech recognition technology can be relevant for humanities research in two ways: it can open up huge amounts of spoken data in archives of which the content is mostly unknown, and it can speed up the lengthy process of manual transcription for scholars who want to analyze their interviews in depth.
The importance of studying speech is evident when taking into consideration the role of recorded voice and moving image for the human expression of the 20th century. Digital tools have already conquered the world of text, magnifying the scale and speed at which phenomena can be observed, but too little attention is given to how we use spoken language and memory to shape our lived experiences into a set of meaningful and coherent stories.
 Workshop participants With this agenda in mind, a mix of Italian, Dutch, British, Czech and German oral historians, linguists, data specialists and speech technologists got together to assess which Digitization, Speech Retrieval, Alignment and Transcription tools are suitable for creating a semi-automated workflow that can turn analogue recordings into readable transcripts. The workshop was supported by CLARIN ERIC, the European infrastructure offering digital data and tools for Digital Humanities scholarly research. It was created to serve a broad range of scholars, but until recently it was foremost a much cherished treasure trove for linguists.
Workshop participants With this agenda in mind, a mix of Italian, Dutch, British, Czech and German oral historians, linguists, data specialists and speech technologists got together to assess which Digitization, Speech Retrieval, Alignment and Transcription tools are suitable for creating a semi-automated workflow that can turn analogue recordings into readable transcripts. The workshop was supported by CLARIN ERIC, the European infrastructure offering digital data and tools for Digital Humanities scholarly research. It was created to serve a broad range of scholars, but until recently it was foremost a much cherished treasure trove for linguists.
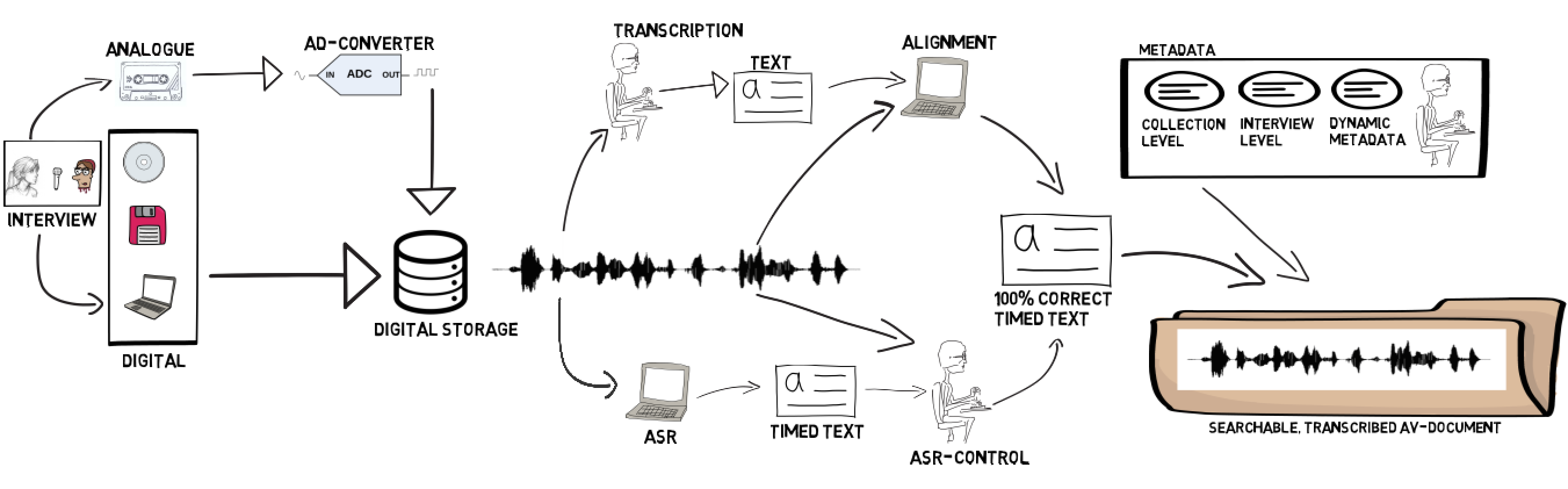 Overview of the 3 steps in the Transcription Chain: from anaolgue to digital to an appropriat digital format, from audio to text, and the addtion of various types of metadata. The increased interest for cross-disciplinary approaches to data is the appropriate context for making efforts to recruit more enthusiastic users from the humanities and social science fields. This objective begs the question of which requirements are relevant to which type of scholar who works with speech data. It also asks scholars to step out of their 'comfort zone' and consider other approaches.
Overview of the 3 steps in the Transcription Chain: from anaolgue to digital to an appropriat digital format, from audio to text, and the addtion of various types of metadata. The increased interest for cross-disciplinary approaches to data is the appropriate context for making efforts to recruit more enthusiastic users from the humanities and social science fields. This objective begs the question of which requirements are relevant to which type of scholar who works with speech data. It also asks scholars to step out of their 'comfort zone' and consider other approaches.
Contributors were asked to present an overview of conventions and practices that should be considered to create a well suited workflow: What are the metadata schemes used in speech data? What are the guidelines for transcription? What are existing digital infrastructures capable of providing? And what has proprietary commercial software already have in store? After the technical partners presented a parade of tools, the real fun part started: testing the various tools with 5 minutes clips of audio.
ASR
The speech recognition tools are of course language-specific. For English they could try out the web service offered by Sheffield University. The Dutch could try out the ASR-service of the Radboud University in Nijmegen, and the Italians could practice with the stand-alone alignment software ‘Segmenta’ created by Piero Cosi at the CNR in Padua.
 Italian Oral Historians around Piero Cosi who explains his ASR-engine As expected, the speech retrieval software performed poorly with clips containing language with strong regional accents, such as a corpus with Tuscan dialect, or an interview with a narrator speaking with a Flemish/Moroccan accent. The good news is however, that it performed excellently with language clips that contained regular speech, and that this applied to all three languages.
Italian Oral Historians around Piero Cosi who explains his ASR-engine As expected, the speech retrieval software performed poorly with clips containing language with strong regional accents, such as a corpus with Tuscan dialect, or an interview with a narrator speaking with a Flemish/Moroccan accent. The good news is however, that it performed excellently with language clips that contained regular speech, and that this applied to all three languages.
For the less technically savvy scholars, it was a surprise to hear how confident speech technologists were about the chances of success when trying to customize speech recognition software to work on non-standard language varieties and lesser-researched languages. The most important requirements seem to be to have enough training material in the form of a lexicon, a language model and an acoustic model that can be fed into the software. Success and low word error rates (WER) appear to be a question of scale, training and perseverance. This might raise new hopes for mobilizing awareness and fostering research on small language groups such as Luxemburgisch.
Transcription tools
The next step in the workflow is the transcription. Several tools were presented, such as OCTRA-2D from München, SubtitleEdit, created by a community of (Danish) developers, and an unexpected contribution from the world of journalism: OTranscribe, which seemed to be the easiest to handle.
The challenge is of course to customize these tools in a way that they can effectively import the outputs of the speech recognition, so that the correction can begin, without having to do any additional clean up or re-structuring.
What was striking when observing the various conventions, is that only sound-based speech studies use time codes. When is comes to studying the interpretation of what is uttered, meaning that you need whole utterances to grasp the meaning and context, there is no tradition of documenting time codes in the metadata. This means that a lot of ‘conversion' in the persuasive sense of the word has to be done, to have humanities and social science scholars make optimal use of digital tools.
Forced Alignment
The last step in the workflow is the alignment, connecting the audio signal to the transcription. This facilitates browsing and searching through an entire corpus of recordings, and can easily be done with ASR output that is not completely correct. For this part of the chain, the Bavarian Archive for Speech Signals has provided WebMAUS, an open source webservice for phoneticians. The demonstration by Christoph Draxler showed that this resource has many more features that could be utilized than was initially known by the organizers.
The Bavarian Archive for Speech Signals already conducts online-experiments and web-based audio transcriptions via crowd-sourcing. Due to the lack of familiarity with other disciplines these functionalities had not been offered to other target groups. These ‘surprises’ were recurrent during the workshop, and showed that mixing disciplines opens up the bubble of your own research network. Programs that for some scholars represent mainstream technology had the impact of real revelations to others.
This was certainly the case with a number of Italian PhD’s. Two moments were exemplary for the diversity in the use of criteria for quality and terminology. The first was when speech technologist Piero Cosi informed linguist Silvia Calamai that her ‘best piece of recording’, had performed the ‘worst’ of all clips. The other was when it became clear that in Thomas Hain's interface for speech recognition, the field ‘metadata’ did not refer to the convention of completing a template with the properties of a document. In this web resource, its function was to encourage uploading textual documents that cover the topic of the sound recording, in order to improve the recognition performance. It was also discovered that linguists and social scientists can mean very different things when they talk about ‘annotation’.
Crowdsourcing
 Henk vd Heuvel and Arjan van Hessen show Afelonne Doek of the IISG how to "recognise" a recorded speech of former Dutch premier "Joop den Uyl" (±1975) A last component of the chain was also considered: creating a community to crowdsource the transcription of an interview collection. The sensational success of crowdsourcing personal written documents, promises good results as long as the workflow is arranged properly. The platform Crowdflower could provide such a structure. With such projects, there are advantages and disadvantages when we compare dedicated platforms such as Crowdflower, or Zooniverse, or consider using our own platforms for crowdsourced projects. Dedicated platforms provide lots of functionality for building and maintaining a community of volunteers, but allowing the researchers limited control over the data and software hosted on the platform. Using our own websites to carry out such projects would require lots of improvements in the user interfaces, and lots of effort to reach people and keep them involved.
Henk vd Heuvel and Arjan van Hessen show Afelonne Doek of the IISG how to "recognise" a recorded speech of former Dutch premier "Joop den Uyl" (±1975) A last component of the chain was also considered: creating a community to crowdsource the transcription of an interview collection. The sensational success of crowdsourcing personal written documents, promises good results as long as the workflow is arranged properly. The platform Crowdflower could provide such a structure. With such projects, there are advantages and disadvantages when we compare dedicated platforms such as Crowdflower, or Zooniverse, or consider using our own platforms for crowdsourced projects. Dedicated platforms provide lots of functionality for building and maintaining a community of volunteers, but allowing the researchers limited control over the data and software hosted on the platform. Using our own websites to carry out such projects would require lots of improvements in the user interfaces, and lots of effort to reach people and keep them involved.
 Group photo in front of the workshop venue: the former psychiatric hospital in Arezzo
Group photo in front of the workshop venue: the former psychiatric hospital in Arezzo
Objections
Of course there were also undercurrents of scepticism, which can ’spoil the party’, but they deserve a prominent role in the assessment of the potential. These refer to the limits of the efficiency of customizing tools that are created by scholars with no commercial interest and who will eventually retire or change jobs.
Another objection was to the top-down approach, the idea that there is a chain and that by customizing existing tools that were created for other purposes, you can cater for a variety of scholars. An alternative would be choosing one discipline, observing all practices attentively, and designing the best tool or tools to fit these practices.
These objections warn against setting no limits to the customization and against presenting the chain as a service to all scholars that will maintained eternally. But academics are not eternal, they are mortal creatures who are supposed to produce new knowledge, not services. On the other hand, these type of arguments can also paralyze creativity and enthusiasm, and the will to collaborate for a common goal. The ideal setting for creating optimal services in a non commercial environment will probably remain a dream. So to push the further development of open source resources we are bound to reach compromises and to take small steps.
 A simple dinner in the trattoria l’Agania in Arezzo.
A simple dinner in the trattoria l’Agania in Arezzo.
Arezzo
The setting in Arezzo was perfect. A mix of nationalities, generations and disciplines engaged in opening up stories about ordinary people, and last but not least, a warm and thoughtful reception by our hosts Silvia Calamai, Francesca Biliotti, Simona Matteini and Caterina Pesce.
For people heading to Arezzo this summer: try La Lancia d’Oro and l’Agania. Readers who want to know more about Oral History and Technology can take a look at the Oral History website curated by Arjan van Hessen and Henk van de Heuvel.
If you are interested in the progress of our effort to create a transcription chain, or are willing to share your experiences with trying out the tools mentioned in this blog, this is the place to be.