
 AI is een buzz-afkorting die nu veel rond zoemt in “onze” wereld. We hebben het over Kunstmatige Intelligentie (KI of AI), Machine Learning (ML) en Deep Learning (DL of DNN). AI is een container begrip dat gebruikt wordt voor niet-menselijke “apparaten” die in onze ogen een vorm van intelligentie vertonen. Arjan sprak tijdens het KSF jaarcongres over de impact van AI op klantcontact en was afgelopen week te gast bij BNR. Reden temeer om samen met Arjan deze blog te schrijven.
AI is een buzz-afkorting die nu veel rond zoemt in “onze” wereld. We hebben het over Kunstmatige Intelligentie (KI of AI), Machine Learning (ML) en Deep Learning (DL of DNN). AI is een container begrip dat gebruikt wordt voor niet-menselijke “apparaten” die in onze ogen een vorm van intelligentie vertonen. Arjan sprak tijdens het KSF jaarcongres over de impact van AI op klantcontact en was afgelopen week te gast bij BNR. Reden temeer om samen met Arjan deze blog te schrijven.
Onttovering van de wereld
 De term Onttovering werd gemunt door de Duitse socioloog Max Weber die in de 19de eeuw zag dat wetenschappelijke verklaringen steeds meer de plek van geloof en magie gingen overnemen. En naarmate de wetenschap steeds wijder verbreid werd, nam het onttoveren toe. Denk bijvoorbeeld aan de bliksem waarvan men vroeger in Noord-Europa dacht dat het kwam van Thor, de dondergod, die zwaaiend met zijn hamer rondreed door de hemel. Het bleek uiteindelijk net iets ander te liggen.
De term Onttovering werd gemunt door de Duitse socioloog Max Weber die in de 19de eeuw zag dat wetenschappelijke verklaringen steeds meer de plek van geloof en magie gingen overnemen. En naarmate de wetenschap steeds wijder verbreid werd, nam het onttoveren toe. Denk bijvoorbeeld aan de bliksem waarvan men vroeger in Noord-Europa dacht dat het kwam van Thor, de dondergod, die zwaaiend met zijn hamer rondreed door de hemel. Het bleek uiteindelijk net iets ander te liggen.
Ook de eerste zichzelf voortbewegende voertuigen (zonder paard of os) riepen in eerste instantie een gevoel van magie op: hoe kan dat? En mijn zelfgebouwd antwoordapparaat dat mij bekende bellers herkende en hen persoonlijk te woord stond (dag Klokkenmakersbedrijf, Arjan kan helaas de telefoon niet opnemen) leidde bij veel bellers tot verbaasde en enthousiaste reacties. Maar als je eenmaal weet hoe het werkt….
Deze onttovering zie je ook bij veel toepassingen van kunstmatige intelligentie: als het er is en goed werkt dan wordt het door de meeste mensen niet langer als werkelijke intelligentie ervaren. Een potje schaken of GO winnen, een smartphone die je verstaat en terugpraat: zodra een computer het kan en de techniek een toepassing vindt, lijkt het weinig meer voor te stellen.
In het hier volgende document zullen we proberen ook Deep Neural Networks een beetje te onttoveren door een beschrijving te geven van de algemene principes waarop het gebaseerd is. Het is niet de bedoeling dat je na afloop zelf een Neural Network in elkaar kunt zetten, maar wel dat je een beetje begrijpt hoe het werkt, welke stappen er ondernomen worden en dat je inzicht krijgt in de mogelijke toepassingen.
Buzz woorden
Kunstmatige intelligentie (AI) en Machine Learning (ML) zijn onderwerpen die op dit moment zeer in de belangstelling staan. Van enthousiaste programmeurs hoor je dat ze ook AI willen leren, van managers dat ze AI in hun diensten willen implementeren. Maar meestal is het een klok-en-klepel verhaal: klinkt als het ei van Columbus maar wat het nu precies is?
Dit artikel is bedoeld om, zonder al te diep in de wiskundige achtergrond te duiken, de basisprincipes van AI en ML uit te leggen. Bovendien zullen we nader ingaan op de op dit moment populairste vorm van ML: Deep Learning.
Artificial Intelligence versus Machine Learning
Artificial Intelligence is het nabootsen van menselijke intelligentie m.b.v. computers/software. Toen AI-onderzoek begon, probeerden onderzoekers menselijke intelligentie voor specifieke taken (bijvoorbeeld voor het spelen van een spelletje) na te bootsen. Ze maakten een lijst met randvoorwaarden die de computer moest respecteren (bij schaken moet je op de 64 velden van het bord blijven spelen) en maakte een lijst van mogelijke acties die de computer kon uitvoeren.
Machine Learning refereert aan de mogelijkheid van computers/software om van grote hoeveelheid data te leren wat er gedaan moet worden. De computer voert dus geen door mensen ingevoerde regels uit. Deze manier van leren maakt gebruik van de enorme rekenkracht van moderne computers – dikwijls via de grafische kaart – en van de mogelijkheid om snel grote hoeveelheden data te kunnen verwerken.
Begeleid versus onbegeleid
Bij begeleid leren (Supervised Learning) werkt de computer met data die een label (=antwoord) heeft Bijvoorbeeld: op deze foto staat een hond, op deze foto niet. Als de computer een verkeerd antwoord geeft, dan zal de manier van berekenen worden aangepast. Dat wordt net zo lang gedaan tot er geen fouten meer gemaakt worden. Denk hierbij aan het sorteren door scholieren van een grote bak met fruit met daarin appels, peren en pruimen. In eerste instantie kunnen de scholieren besluiten te selecteren op basis van grootte. Dat werkt niet goed want je hebt grote pruimen en kleine appels. De fruitteler beziet het resultaat en geeft aan welke sorteringen goed en welke fout waren. Vervolgens gaan de scholieren selecteren op kleur. Ook dit werkt niet goed en weer krijgen ze te horen wat er goed en fout ging. Dit gaat een tijdje zo door, tot de scholieren “begrijpen” dat ze op kleur, vorm en textuur moeten selecteren. Langzaamaan worden ze steeds beter en uit eindelijk zullen ze, uitzonderingen daar gelaten, geen fruit meer verwisselen. Op precies deze wijze werkt “begeleid leren”. In 2016 gebruikte de Japanse komkommerkweker Makoto Koike deze vorm van leren om zijn gekweekte komkommers te selecteren op rechte en kromme (zie hier).
 Video van het zelfgebouwde komkommer selecteerapparaat van Makoto Koike
Video van het zelfgebouwde komkommer selecteerapparaat van Makoto Koike
Bij onbegeleid leren bestaat de invoer uit ongelabelde data en moet de computer zelf uitzoeken wat de bedoeling is. Het kan bijvoorbeeld de bedoeling zijn dat de data in N groepjes “op elkaar gelijkende data” moet worden verdeeld. De computer moet dan maar uitzoeken wat het optimale aantal groepjes is en welke criteria voor die onderverdeling gebruikt moeten worden.
Een voorbeeld van onbegeleid leren is het voorspellen van het gedrag van bezoekers van een e-commerce website. Het algoritme kan zijn eigen classificatie maken waarbij elke klasse bestaat uit personen die gelijksoortige producten kopen. Een uitkomst kan zijn “mannen kopen bier, vrouwen nagellak” maar ook een veel verfijndere verdeling waarbij niet het geslacht maar leeftijd, opleiding, inkomen, woonplaats en tijdstip van websitebezoek de discriminerende parameters zijn.
Scopa
Toen ik eind jaren zeventig met een studiegenoot voor onze studie geofysica naar een piepklein dorpje in de Apennijnen werd gestuurd, bestond onze kennis van het Italiaans uit “Si, Non, Pizza, Birra, uno, Due en Macaroni”. Niet echt een woordenschat waar je veel verder mee komt. In de avonduren werden wij door de nieuwsgierige oudere mannen uitgenodigd om aan hun tafel te komen zitten alwaar ze een voor ons volkomen onbekend kaartspelletje speelden met ook nog vreemde kaarten.
 Italiaanse kaarten om Scopa mee te spelen.
Italiaanse kaarten om Scopa mee te spelen.
Na een paar avonden vroegen ze ons (met handen en voeten) of we mee wilde spelen. Nou, dat was een uitdaging. We begrepen in eerste instantie noch de invoer (=kaarten) noch de selectiecriteria (de spelregels). Het enige dat we konden doen was goed kijken naar hetgeen zij deden. Als eerste begrepen we dat om de beurt (met de klok mee) een van de spelers aan de beurt was en dat iemand gewonnen had wanneer hij heel hard Scopa riep. Uiteindelijk leerden we het spel door goed te kijken en te proberen enkele spelregels te ontdekken: een pure vorm van ongeleid leren. Toen we een paar basisregels ontdekt hadden en mochten meespelen (het dorpje was zo klein dat ze een gebrek aan spelers hadden) veranderde het onbegeleid leren spelen in begeleid leren spelen doordat we bij iedere fout op ons donder kregen.
Deep Learning en Neurale Netwerken
Deep Learning is een speciale vorm van Machine Learning waarbij gebruik wordt gemaakt van Neurale Netwerken. Het kan gebruikt worden voor zowel begeleid als onbegeleid leren. Wij mensen hebben tussen de 80 en 90 miljard neuronen in onze hersenen. Neuronen zijn cellen in ons zenuwstelsel en zorgen voor het ontvangen en verzenden van zenuwprikkels. Neuronen zitten aan elkaar via dendrieten en neurieten. Informatie wordt via deze verbindingen doorgegeven en opgeslagen.
 Voorbeeld van een menselijk neuraal netwerk.
Voorbeeld van een menselijk neuraal netwerk.
Een kunstmatig Neural Network bestaat uit lagen met knooppunten (cellen) met invoer (vanuit alle cellen van een eerdere laag) en uitvoer (naar alle cellen in de volgende laag). Iedere cel vermenigvuldigt alle waarden die binnenkomen met een getal en stuurt het resultaat dan door naar alle cellen in de volgende laag.
Een Neural Network bestaat uit drie soorten lagen: de invoerlaag, de uitvoerlaag en een aantal tussen lagen (verborgen lagen). Vroeger , jaren 90, was er maar een tussenlaag. Computers konden niet meer aan. De laatste jaren is dat geen probleem meer en hebben de neurale netwerken een groot aantal lagen: vandaar de naam Deep Neural networks.
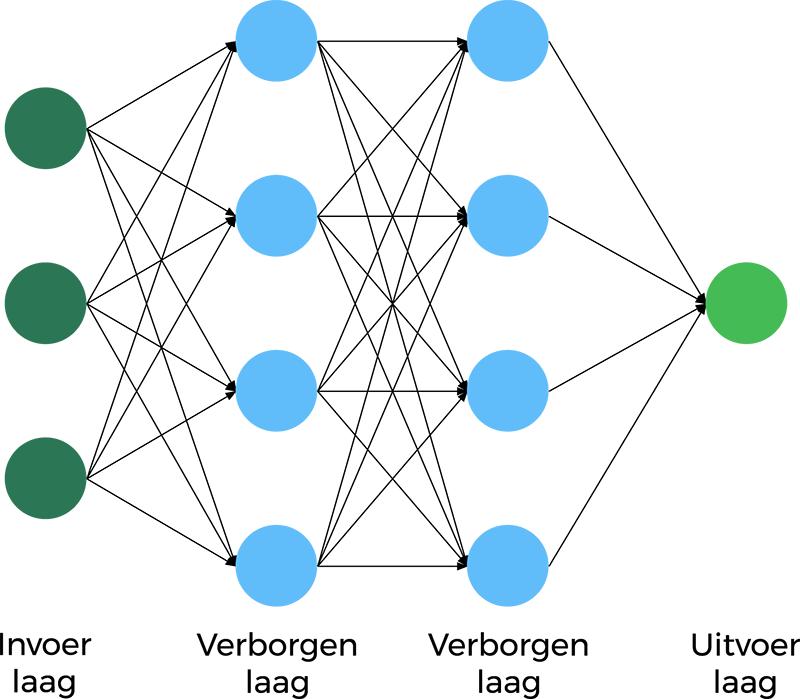 Schematisch beeld van een Neural Network met input, output en tussenlagen.
Schematisch beeld van een Neural Network met input, output en tussenlagen.Voorbeeld
We zullen nu een fictief voorbeeld gebruiken. We willen een netwerk maken dat, gegeven een paar parameters, de prijs van brandstof schat. De 4 parameters die we hebben zijn “merk brandstof (bijvoorbeeld Shell of Esso), locatie (snelweg, industrieterrein, in dorpskern, etc.), datum en tijdstip van tanken (op het uur nauwkeurig) en de officiële brandstofprijs. De invoerlaag ontvangt van iedere dataset deze 4 inputgegevens. De invoerlaag vermenigvuldigt de waarden en geeft ze door naar de eerste verborgen laag.
De verborgen lagen (2 in dit voorbeeld) voeren wiskundige berekeningen uit op onze input. Een van de uitdagingen bij het creëren van neurale netwerken is het bepalen van het aantal verborgen lagen, evenals het aantal neuronen voor elke laag. De uitvoerlaag geeft “het antwoord”, bijvoorbeeld wat kost een liter diesel waarschijnlijk.
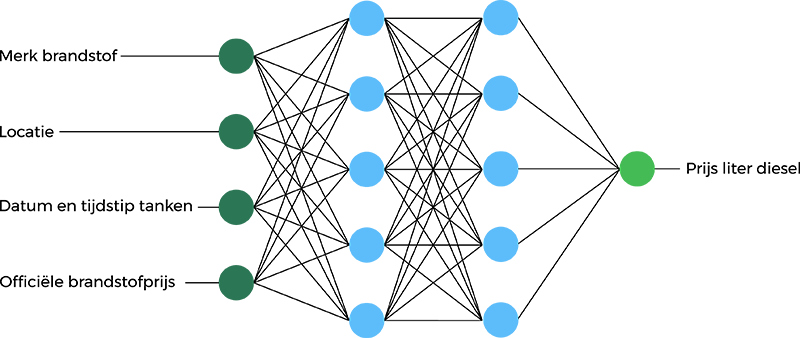 Voorbeeld network voor het berekenen van de brandstofprijs.
Voorbeeld network voor het berekenen van de brandstofprijs.Hoe rekent een DNN?
Elke verbinding tussen neuronen wordt geassocieerd met een “gewicht”. Dit gewicht bepaalt het belang van de invoerwaarde. Als we een DNN de eerste keer starten, krijgen alle neuronen een random waarde tussen 0 en 1. Bij het voorspellen van de prijs van de brandstofprijs is het merk één van de zwaardere factoren. Het neuron met het brandstofmerk zal dus een groot gewicht hebben. Elke neuron heeft een activeringsfunctie. Het voert iets te ver om die helemaal uit te leggen, maar het is een formule die berekent met welke waarde de invoerparameter vermenigvuldigd wordt. Iedere neuron voert deze actie uit op alle invoerwaarden en geeft het resultaat door naar de neuronen in de volgende laag. Uiteindelijk resulteren al deze acties in een geschatte brandstofprijs.
Trainen van het Neural Network
Het trainen van het netwerk is het lastigste onderdeel van Deep Learning omdat:
- Je veel data nodig hebt.
- Je veel rekenkracht nodig hebt.
Als eerste hebben we veel data nodig met locatie, merk, datum, tijd en de prijs van de brandstof waarmee we het netwerk gaan trainen. De eerste keer zijn alle vermenigvuldigingswaarde van de neuronen random gekozen en dus zal het eindresultaat (de schatting van de brandstofprijs) verkeerd zijn. Als we eenmaal alle data door het netwerk gestuurd hebben, kunnen we een functie creëren die ons laat zien hoe verschillend de geschatte brandstofprijzen van de echte brandstofprijzen waren. Deze functie wordt de kostenfunctie genoemd. In het ideale geval willen we dat deze kostenfunctie nul is want dan zijn de kosten nul en is de geschatte prijs exact gelijk aan de werkelijke prijs.
Hoe kunnen we kosten reduceren?
Een aanpak is “proberen”. Gewoon net zolang de waarde van de verschillende neuron veranderen tot we een goed resultaat krijgen. Dit zou kunnen werken, maar is weinig efficiënt. Een andere aanpak is gebruik te maken van iets dat Gradient Descent heet. Het is een techniek die het mogelijk maakt het minimum van de kostfunctie te berekenen. Het werkt door de gewichten van de neuronen in kleine stappen te wijzigen na elke iteratie. Door de afgeleide ofwel verandering van de kostenfunctie te berekenen, kunnen we zien in welke richting het minimum ligt.
Om dit goed te kunnen doen, moeten we vele malen itereren en dat is precies de reden dat we veel rekenkracht nodig hebben. Een bijkomend voordeel van het gebruik van de Gradient Descent methode, is dat de gewichten van de neuronen vanzelf worden bijgewerkt.
Als we eenmaal op deze wijze het minimum hebben gevonden, zijn we klaar. De gewichten staan nu zo ingesteld dat ze, gegeven de trainingsset, de uitkomst het best schatten. De verwachting is dan dat, als de data de werkelijkheid daadwerkelijk representeren, het model ook bij nieuwe data, de brandstofprijs goed zal voorspellen.
 Schematische weergave van de kostfunctie en z’n minimum.
Schematische weergave van de kostfunctie en z’n minimum.Waar kan ik meer leren?
Er zijn tegenwoordig heel veel onlinecursussen over Kunstmatige Intelligentie. Sommigen zijn meer beschrijvend terwijl anderen meer op het coderen ingaan: hoe maak je nu zelf zo’n AI-netwerk. Daarbij is het goed te weten dat er verschillende netwerken voor verschillende toepassingen zijn: Convolutional Neural Networks voor Computer Vision en Recurrent Neural Networks voor Natural Language Processing.
Op dit moment is de Deep Learning Specialization cursus van //medium.com/@andrewng">Andrew Ng, een van de grondleggers van de huidige AI’s, een van de beste om te volgen. En zo lang je geen certificaat wilt, is de cursus gratis te volgen.
Conclusie
Het gebruik van Neural Networks in de wereld van AI is zeker niet triviaal. De technologie achter de Deep Neural Networks is behoorlijk ingewikkeld, en het is niet iets dat je op een achternamiddag maakt.
Maar het basisidee van DNN’s is goed te begrijpen, ook zonder en gedegen kennis van de wiskunde. Vergelijk dit met het begrijpen hoe een auto werkt. Dit kun je goed begrijpen, maar zelf een auto in elkaar sleutelen is toch wel andere koek.
Referenties
Dit artikel is gebaseerd op een interessante blog. Andere interessant leesvoer:
- https://decorrespondent.nl/2064/voorbij-sciencefiction-hoe-reeel-is-het-gevaar-van-kunstmatige-intelligentie/384791637648-487b0039
- http://natureofcode.com/book/chapter-10-neural-networks/
- https://medium.com/towards-data-science/deep-learning-specialization-by-andrew-ng-21-lessons-learned-15ffaaef627c