
19 feb 2016
Seminar (Her)gebruik en betere doorzoekbaarheid van videomateriaalBijeenkomst - Nu video in steeds grotere getale wordt geproduceerd en gebruikt staan onderwijsinstellingen voor het vraagstuk hoe zij haar videomaterialen zo goed mogelijk vindbaar kunnen maken. Dat geldt zowel voor het vinden van video’s als voor momenten in videobestanden. Op vrijdag 19 februari 2016 worden een aantal "best practices" op Europees niveau getoond.
|
 Op mijn verjaardag had ik de eer een lezing bij SURF te mogen houden over het gebruik van "Taal- en Spraaktechnologie voor het semi-automatisch ontsluiten van WebLectures" (zeg maar opgenomen colleges). Naarmate er meer en meer colleges opgenomen worden en aan eigen studenten, studenten van de faculteit, studenten van de eigen universiteit of zelfs aan iedereen beschikbaar worden gesteld, wordt het steeds belangrijker om de juiste metadata toe te voegen. Zonder dit wordt het zoeken naar de juiste fragmenten steeds lastiger en omdat er zoveel materiaal beschikbaar komt, houdt het in dat het credo "niet gevonden, niet bestaat" weer gaat gelden.
Op mijn verjaardag had ik de eer een lezing bij SURF te mogen houden over het gebruik van "Taal- en Spraaktechnologie voor het semi-automatisch ontsluiten van WebLectures" (zeg maar opgenomen colleges). Naarmate er meer en meer colleges opgenomen worden en aan eigen studenten, studenten van de faculteit, studenten van de eigen universiteit of zelfs aan iedereen beschikbaar worden gesteld, wordt het steeds belangrijker om de juiste metadata toe te voegen. Zonder dit wordt het zoeken naar de juiste fragmenten steeds lastiger en omdat er zoveel materiaal beschikbaar komt, houdt het in dat het credo "niet gevonden, niet bestaat" weer gaat gelden.
Welke metadata
Als over metadata gesproken wordt, is niet altijd duidelijk welke metadata bedoeld wordt. Er zijn eigen drie soorten metadata:
- De "harde" metadata over het bestand, de rechten erop, datum, maker en meer. Dit wordt dikwijls voldoende af gedekt met de Dublin Core (DC) metadata. Maar DC zegt niets over de inhoud.
- De beschrijvende metadata. Hier komen zaken als de inhoud, tijdsperiode, namen en meer. Maar.... dit is op bestandsniveau (dus over het hele college).
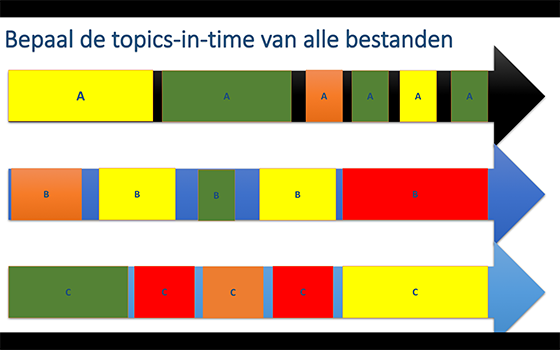
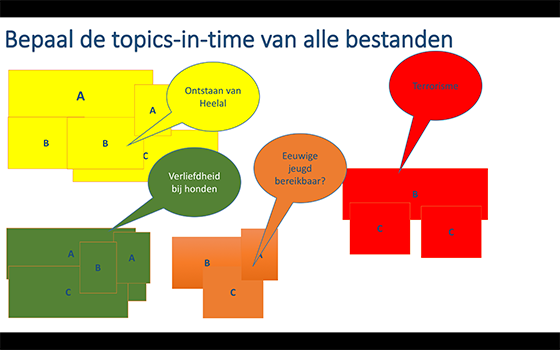
- Tijdgerelateerde metadata: dit zijn de beschrijvingen over delen van het college. Bv de eerste 5 minuten gaan over de schrijvers in de Gouden Eeuw. De 10 minuten daarna over de specifieke schilder. etc.
Dit laatste biedt veel voordelen. Door van de colleges steeds op te geven waarover het gaat, kunnen later op betrekkelijk eenvoudige wijze nieuwe video-programma's gemaakt worden. Stel dat je van 10 bestaande video-lessen weet welke fragmenten over de jonge Rembrandt gaan, dan kun je door alleen die fragmenten bij elkaar te zetten, een les over de jonge Rembrandt maken of op z'n minst studenten die opzoek zijn naar "iets" van de jonge Rembrandt, een verzameling video-fragmenten aanbieden.
 |
 |
De lezing
De lezing met PowerPoint voor een bomvolle zaal (>70) ging verder goed (30 min) en na afloop nagepraat met een aantal mensen van de Radboud, Erasmus en UvA die allemaal ook bezig zijn met uit te zoeken hoe ze het best hun collecties kunnen ontstluiten. Silvia Moes, de organisator, was tevreden met het praatje en wil op korte termijn doorpraten over een nationaal en wellicht Europees project (aan te vragen). Klinkt goed en op 7 maart gaan we praten.
Voor wie
Wat opviel was dat het idee dat je een (hoor-)college opneemt voor iedereen die er in geïnteresseerd is, niet bij iedereen leeft. Veel docenten vinden dat het alleen maar voor de eigen studenten bedoeld is, anderen juist voor de hele wereld en de meesten zitten daar waarschijnlijk tussen in. Verschillende sprekers en vragenstellers hadden dit ook al opgemerkt en aangegeven dat dit best lastig is. Een bijkomend probleem is dat veel docenten zich volstrekt niet realiseren dat er copyright rust op het gebruik van bv foto's , plaatjes of ander materiaal tijdens het college. Je mag dus iet zomaar een foto van een gebouw tonen als je daar officieel geen toestemming voor hebt. Iedereen doet dat natuurlijk tijdens het college en iemand zal er over vallen, maar als je het college de wereld in streamed, dan ligt dat anders.Lastig maar ook boeiend!
