
Sinds 2016 zijn DNN, AI, ML buzz-afkortingen die rondzoemen in de "onze" wereld. In het kader van een voorlichtingsfilmpje dat we in de herfst van 2016 voor Telecats gaan maken, was het logisch eens wat materiaal op te zoeken dat gebruikt zou kunnen worden om een en ander te verduidelijken: zowel voor mijzelf als voor anderen 
Wat is nu precie het verschil tussen de verschillende technieken? We hebben Kunstmatige Intelligentie (KI of AI), Machine Learning (ML) en Deep Learning (DL of DNN). AI is meer een container begrip dat gebruikt wordt voor niet-menselijke "apparaten" (fysiek of virtueel) die in onze ogen (dwz van ons mensen) een vorm van intelligentie vertonen. In het ideale geval (dwz als het allemaal goed werkt) zou een mens in een test het verschil tussen de computer en een mens niet kunnen maken. Dit staat bekend als de Turing Test. In experimenten die overal over mogen gaan, is dit nog niet gelukt, maar voor zeer speciefieke domeinen is soms al niet meer mogelijk om het verschil te maken.
Machine Learning
Kunstmatige intelligentie is al een begrip sinds de jaren '50 maar heeft altijd een hoog SF gehalte gehad. Sinds een aantal jaren is er Machinen Learning. ML kan gezien worden als een vorm van patroonherkenning waarbij de computer zelf bepaalt hoe "parameters" gewogen moeten worden om invoer zo goed mogelijk te mappen op uitvoer. Een mooi voorbeeld is het onderzoek naar de G2P (Grapheme-to-Phoneme) conversie. Een G2P zet geschreven woorden (dwz gewone tekst) om naar de uitspraak van die woorden. Appel klinkt als /Ap-@l/ maar Appêl klinkt als /Ap-El/. In zijn proefschrift laat Antal vd Bosch mooi zien hoe je de computer kunt leren hoe de verschillende letters uit te spreken door steeds 5 (of 7 of 9) opeenvolgende letter aan te bieden en dan van de middelste letter te zeggen hoe die klinkt. We hebben dat in algoritme gebruikt voor onze spraakherkenner op de UTwente en het werkte goed; eigenlijk beter dan de meer regelgebaseerde G2P's die tot die tijd gebruikt werden. Deze aanpak werkt wanneer je veel voorbeelden hebt. We hebben indertijd de Grote Van Dale gebruikt: 1.3 M woorden. En nee, soms gaat het fout omdat er altijd uitzonderingen zijn: woorden die net anders worden uitgeschreven dan "je zou verwachten".
Deep Learning
 Met de komst van Internet, cloud computing en betere algoritmes werd het mogelijk om niet honderden voorbeelden te gebruiken maar miljoenen! Een van de eerste spraakmakende voorbeelden (2012) van het gebruik van Deep Learning was het door Google ontwikkelde systeem om plaatjes van katten te kunnen herkennen. Ook andere grote bedrijven als Microsoft, Amazon, Apple, HP en Facebook kwamen met mooie voorbeelden waarbij Deep Learning (of wel het leren mbv Deep Neural Networks of DNN's) gebruikt wordt. Een aansprekend voorbeeld was het gebruik van DNN's door Microsoft om veel beter spraak te herkennen (Microsoft/InterSpeech, 2011). In de voorafgaande jaren was de herkenning slechts met veel moeite een beetje beter geworden: het leek of we tegen een soort plafond aan liepen waar we maar niet doorheen konden. Na de presentatie van Microsoft storte iedereen zich op DNN's en ASR met gevolg dat de herkenningsresultaten heel snel veel beter werden. Op dit moment is het al mainstream geworden en zijn er allerlei Open Soucrce inititiatieven zoals KALDI waar iedereen die dat wil (en kan) gebruik kan maken van DNN's voor betere herkenning. In Nederland is Laurens van der Werff hard bezig een zeer goede Open Source DNN-gebaseerde herkenning te ontwikkelen (in samenwerking met Beeld&Geluid, de UTwente, de Nederlandse Politie en de FIOD).
Met de komst van Internet, cloud computing en betere algoritmes werd het mogelijk om niet honderden voorbeelden te gebruiken maar miljoenen! Een van de eerste spraakmakende voorbeelden (2012) van het gebruik van Deep Learning was het door Google ontwikkelde systeem om plaatjes van katten te kunnen herkennen. Ook andere grote bedrijven als Microsoft, Amazon, Apple, HP en Facebook kwamen met mooie voorbeelden waarbij Deep Learning (of wel het leren mbv Deep Neural Networks of DNN's) gebruikt wordt. Een aansprekend voorbeeld was het gebruik van DNN's door Microsoft om veel beter spraak te herkennen (Microsoft/InterSpeech, 2011). In de voorafgaande jaren was de herkenning slechts met veel moeite een beetje beter geworden: het leek of we tegen een soort plafond aan liepen waar we maar niet doorheen konden. Na de presentatie van Microsoft storte iedereen zich op DNN's en ASR met gevolg dat de herkenningsresultaten heel snel veel beter werden. Op dit moment is het al mainstream geworden en zijn er allerlei Open Soucrce inititiatieven zoals KALDI waar iedereen die dat wil (en kan) gebruik kan maken van DNN's voor betere herkenning. In Nederland is Laurens van der Werff hard bezig een zeer goede Open Source DNN-gebaseerde herkenning te ontwikkelen (in samenwerking met Beeld&Geluid, de UTwente, de Nederlandse Politie en de FIOD).
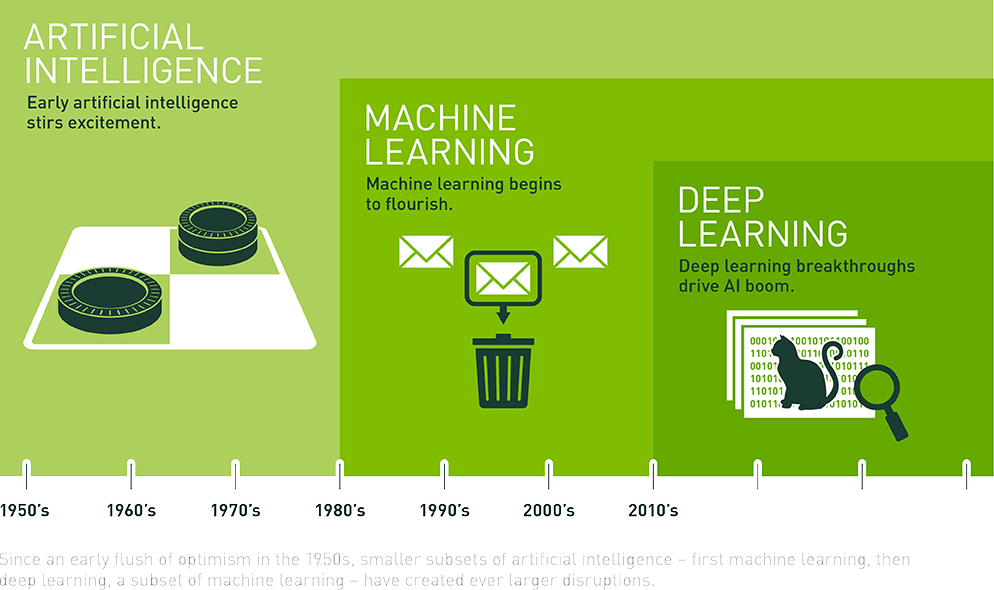 Meer in het algemeen kan gesteld worden dat Deep Learning een speciale versie is van Machine Learning en dat ML weer een onderdeel is van "Kunstmatige Intelligentie" (zie plaatje hiernaast).
Meer in het algemeen kan gesteld worden dat Deep Learning een speciale versie is van Machine Learning en dat ML weer een onderdeel is van "Kunstmatige Intelligentie" (zie plaatje hiernaast).
Met de komst van zulke krachtige systemen waarmee je gewoon heel veel voorbeelden geeft (dit woord klinkt als..., op dit plaatje staat een kat, etc.) en eigenlijk zegt "zoek het verder zelf maar uit", wordt het mogelijk en zelfs makkelijk om deze technologie in heel veel andere processen in te zetten.
Van de Labs naar de Wereld
De laatste jaren zien we de AI al "de wereld" insluipen. Zonder al te veel publiciteit worden bestaande en nieuwe applicaties uitgerust met AI en dat zal de komende jaren alleen maar toenemen."Kunstmatige Intelligentie" zal op grote schaal worden toegepast in steeds meer verschillende toepassingsgebieden.
Zo wordt IBM's Watson al gebruikt voor "legal issues" en "health care", zet Google de "Image Recognition" van de kattenplaatjes in voor het herkennen van vrienden in je eigen fotoalbums, gebruikt Amazon het voor haar Alexa (Echo) platform en experimenteren verschillende (auto)bedrijven met AI voor voertuigondersteuning en zelfsturende voertuigen. In al deze voorbeelden zien we dat AI gebruikt wordt om routinematige menselijke kennis te modelleren. Het is zelf rijden gaat daarom vaak goed, maar onverwachte situaties die buiten de "normale" gang van zaken vallen, geven nog (te) vaak problemen.
Klantcontact
Een van de gebieden waar AI zonder twijfel zal worden ingezet is in de (virtuele) mens-machine interactie (MMI). In alle contacten-op-afstand (web, telefoon, chat) waarbij mensen "iets willen" van een organisatie/bedrijf speelt de door ervaring opgedane kennis van de medewerkers een grote rol: zij weten immers hoe een vraag geduid en beantwoord moet worden, wat klanten prettig vinden of juist niet en hoe het doel van zowel de klant als het bedrijf het best gehaald kan worden.
Deze kennis is er niet zomaar maar moet door medewerkers worden verworven. Dat gebeurt door aparte training, training on-the-job, hulp van ervaren collega's en een portie "gezond verstand". Naarmate een medewerker langer met de klanten werkt, zal hij/zij beter en sneller kunnen inschatten hoe iemand het best geholpen kan worden. Dat is niet veel anders met AI-systemen. Door alle vraag-antwoord combinaties te (blijven) verzamelen en de AI-engine daar (steeds opnieuw) mee te trainen, kan zo'n engine ook "leren" hoe met vragen omgegaan moeten worden. Voordat we nader ingaan op de toepassingen, eerst een overzicht van de drie pijlers waarop AI rust bij de klantcontacten.
Voordat we naar de daadwerkelijke toepassingen kijken, behandelen we eerst de drie basiselementen van AI binnen de klantcontacten:

| Assess | Kijk goed naar alle data die je kunt krijgen. Verwijder die data die je niet wilt gebruiken cq. iet relevant is. Probeer aan de hand van de "schone" data, in te schatten wat er "gebeurt". |
| Predict | Probeer aan de hand van data die de huidige situatie beschrijven, in te schatten wat er zal gebeuren. |
| Advise | Geef advies op maat, gebaseerd op en de verwachting (predictie) en de "wens" van de geadviseerde. Het advies zal altijd afhankelijk zijn van de doelstelling van de geadviseerde. Het advies zal anders zijn als de opdrachtgever zo snel mogelijk alle minder-renderende gesprekken de self-service in wil duwen dan wanneer juist alle bellers "optimaal" geholpen moeten worden. |
In veel toepassingen op het gebeid van klantcontacten gaat het er om het zo goed mogelijk te voorspellen wat het gedrag van gebruikers zal zijn, gegeven een bepaalde situatie (dag van de week, temperatuur, deel van het jaar, regen/geen regen, etc.). Door zoveel van dit soort data op te slaan, kan een mogelijk verband gevonden worden. Wel moet worden opgelet niet in de bekende valkuil te vallen: correlatie is iets anders dan causaliteit!
Bij klantcontacten onderscheiden we 4 verschillende stadia:
 |
Wie neemt er contact op? Kunnen we door een paar slimme vragen en gebruik makend van aanwezige gegevens, erachter komen wie er contact opneemt? |  |
Waarom doet ie dat? Wat is de reden dat iemand contact zoekt? Probeer er achter te komen door het te vragen en combineer de herkende antwoorden met aanwezige predictie. |
 |
Wat doe ik er mee? Wat doe je met het gesprek als je weet wie er waarom contact zoekt? Combineer ook hier de "berekende" informatie met aanwezige predictie. |
 |
Analyse. Wat valt er over deze contact poging te zeggen, gegeven alle andere contact pogingen? Analyseer en herbereken de verschillende kansen gegeven de nieuwe invoer. |
De eerste drie stappen geven al een hoop informatie. Als je weet wie er contact zoekt, dan weet je (meestal) ook meer van die persoon (gender, leeftijd, herkomst, etc.) Weet je wat de vraag is, dan kun je alle gegevens combineren om te schatten welke actie je het best kunt ondernemen. Niet iedere beslissing die je uiteindelijk neemt zal juist zijn. Laat medewerkers de uiteindelijk genomen beslissing controleren (dwz aanpassen als het fout was) en sla ook het gecorrigeerde antwoord op. Deze reeks met gegevens wordt weer teruggegeven aan het systeem dat "leert" hoer het beter kan. Op deze manier wordt de tijd meegenomen: vernderen de vragen en/of de recties op de vragen dan zal het systeem dit leren.
Predictive Analytics
De verschillende statistische technieken die hier gebruikt worden ("predictive modeling", "machine learning", en "data mining") staan bekend als Predictive Analytics; ze proberen onbekende items te vullen (Predict) op basis van bestaande informatie (Assess). Die onbkende items kunnen iets in de toekomst zijn (voorspellen) of iets dat niet bekend is (inschatten).
Een mooi overzicht van het hierboven beschrevenen is te vinden in het onderstaande filmpje (≈ 1 uur) van Kristian Hammond.

Toekomst
Wat gaat de toekomst brengen? Hieronder wat vragen en mogelijke antwoorden mbt AI.
Wat is AI, machine learning en hoe werkt het?
Wat zijn de voorwaarden voor verdere ontwikkeling van AI en welke rol speelt b.v. de wet van More?
 De Wet van Moore stelt dat de rekenkracht iedere 2 jaar verdubbelt. Dat is op den duur niet meer houdbaar, maar voorlopig kunnen we er van uitgaan dat we over 7 jaar een 10x grotere rekenkracht tot onze beschikking hebben. De Wet van Moore geldt voor individuele computers maar door de opkomst van Cloud Computing en het gebruik van GPU (ipv CPU) hebben we eigenlijk nu al een onbeperkte rekencapaciteit tot onze beschikking. En ja, die zal voorlopig aaleen maar sterk toenemen.
De Wet van Moore stelt dat de rekenkracht iedere 2 jaar verdubbelt. Dat is op den duur niet meer houdbaar, maar voorlopig kunnen we er van uitgaan dat we over 7 jaar een 10x grotere rekenkracht tot onze beschikking hebben. De Wet van Moore geldt voor individuele computers maar door de opkomst van Cloud Computing en het gebruik van GPU (ipv CPU) hebben we eigenlijk nu al een onbeperkte rekencapaciteit tot onze beschikking. En ja, die zal voorlopig aaleen maar sterk toenemen.
AI is in de leer-fase behoorlijk reken-hongerig en dus zal de toename van de rekenkracht (en die van de beschikbare hoeveelheid data) er voor zorgen dat AI heel snel heel veel krachtiger gaat worden.
Hoe verhoudt AI, machine learning zich tot de spraaktechnologie van Telecats?
Telecats gaat over niet al te lange tijd gebruik maken van de op KALDI-ASR gebaseerde spraakherkenner. Dat soort ASR engines worden verschrikkelijk goed en dus zal ook de WER bij de door Telecats gehoste services, omlaag gaan. State-of-the-Art herkenners van dit moment zitten qua WER nog maar een heel klein beetje boven dat van de mens. Maar dat geldt voor speciale "beschrenkte" taken en voor het Amerikaans-Engels. Voor "gewone" herkenning in het Nederlands, is er nog wel een weg te gaan. Hoe komt dat? Wij mensen zijn gewoon heel goed in het horen van wat er bedoeld zou kunnen worden. We horen iets en met onze verwachtingen over wat er gezegd gaat worden, vullen we al het ware in wat we horen. Vaak klopt dat, maar lang niet altijd. Dit is ook de reden dat we een spraak in een voor ons minder vertrouwde taal, slechter herkennen. De spraakherkenning zal er dus enorm baat bij kunnen hebben wanneer we dat proces onder de knie krijgen: het kunnen voorspellen van hetgeen er gezegd gaat worden en de spraak daaraan oplijnen.
Hoe en welke rol speelt AI nu al in klantcontact?
Het is lastig om dit te beantwoorden omdat niet altijd duidelijk is welke AI-componenten er in welke Klantcontactsoftware gebruikt wordt. Wat wel kan is een beeld geven van de mogelijkheden die AI hier biedt. Als bedrijven hun data goed op orde hebben dan kunnen ze de Predictive Analytics zoals hierboven uitgelegd, gebruiken om veel beter te kunnen voorspellen wanneer er wat voor (soort) vragen gesteld zullen worden. Bovendien kan AI helpen bij het beter afhandelen van de klanten. Enerzjijds door een betere herkenning anderzijds door een betere routering en/of automatische beantwoording van de vragen. Als duidelijk is wat de klant wil, dan zou Natural Language Generation (NLG) wel eens een grote rol kunnen gaan spelen. NLG is het proces om van data een goed lopende zin te maken. Zo'n zin kan dan uitgesproken worden maar ook gemaild / geWhatsAppt kunnen worden.
Voorbeeld: Je belt de gemeente met een vraag over je bouwvergunning. In het systeem staan een aantal parameters (datum, goedgekeurd/afgekeurd, benodigdheden en meer). NLG kan van deze parameters een mooi lopende zin maken die voor de klant begrijpelijk is.
Hoe en welke rol gaat AI in de nabije toekomst bij klantcontact spelen?
AI maakt het mogelijk om op een veel serieuzere manier de klanten te helpen. 20 jaar geleden begon de self-service met het indrukken van een telefoontoets (toets 1 voor...) Daarna kwam de eenvoudige spraakherkenning waarbij een onderwerp geadresseerd kon worden middels het inspreken van een naam (van welk naar welk station in Nederland wilt u reizen?). Zo'n 10 jaar geleden werd het mogelijk om met hele volzinnen te antwoorden (Spreek kort de reden in waarom u ons belt). Naarmate de spraakherkenning beter werd, kon men complexere zinnen inspreken. Maar zelf met 100% correcte spraakherkenning bleef het lastig om een adequaat antwoord te geven op elke vraag. Hier kan AI een doorbraak betekenen omdat het systeem nu zelf kan gaan leren hoe een herkende uiting afgehandeld moet worden. Het geeft de mogelijkheid om de laatste barriere te nemen: van herkennen naar begrijpen!
Welke rol gaan SIRI en de andere personal (mobile) assistenten en b.v. Echo van Amazon spelen?
Op InterSpeech 2015 maakte Ruhi Sarikaya (Microsoft) in zijn keynote duidelijk dat hij de rol van de Cortana's, SIRI, Alexa en Google Now van deze wereld ziet als die van een uber-app die alle andere apps gaat aansturen. Waarom een aparte NS-app, een OV-app voor Utrecht en eentje voor Enschede als je straks vanuit de een voice-assisted app alle info kunt opvragen? Wellicht worden die andere apps meer een soort widget die wel de juiste info kunnen ophalen/brengen maar gebeurt de aansturing via de spraakinterface van de voice-controlled apps als SIRI. Als dat gebeurt, dan zal een deel van de klantcontacten op deze manier afgehandeld worden. Waarom bellen als je gewoon op je telefoon je vraag kunt inspreken (SIRI: vraag Bol.com, wanneer mijn leunstoel wordt bezorgd?)
Er zijn mensen zoals Elon Musk die AI toepassen, maar ook gelijk waarschuwen voor het gevaar van AI. Wat is het gevaar?
De grote angst van AI is dat ze eens een beslissende rol in het intermenselijke verkeer zullen gaan innemen. Vergelijk het met de buraucratische nachtmerrie die je soms krijgt als je iets bij de overheid wilt regelen. Je wilt iets iets doen, iedereen is het met je eens, vindt het een goed idee en wil je graag helpen maar ja, de regels....
Stel nu dat AI-gedreven computersystemen tzt beslissingen nemen die geheel indruisen tegen elke menselijke logica. Iedereen is het er over eens dat dat niet kan, maar ja.... de beslissingsmacht ligt ergens anders (nl bij die super logisch redenerende systemen). Een stap verder gaan de angstvisioenen dat AI de wereld overneemt en de mens vernietigt.
Een van de bekenste en mooiste voorbeelden is natuurlijk HAL die astronaut Dave buitensluit wanneer die de computer wil uitzetten.
Dave: Open the pod bay doors, HAL.
HAL: I'm sorry, Dave. I'm afraid I can't do that.

Of deze angst terecht is of niet is op dit moment niet duidelijk. Wel dat het iets waar men zich druk over maakt en het is precies daarom dat de grote computerbedrijven een soort overrule-button in hun software willen inbouwen waarmee het systeem ten alle tijden uitgezet kan worden. Om dit te regelen zijn de grote AI-bedrijven recent een samenwerking aangegaan die het overrulen van machines moet voorkomen.
Wat zijn de grootste veranderingen door AI voor de komende jaren? (niet alleen in klantcontact)
De grootste veranderingen die we door de steeds grotere aanwezigheid van AI zullen zien, is dat er massaal slimmem systemen zullen komen die van "ons" zullen leren en vervolgens met ons zullen interacteren. Gezondheidszorg, financiele planning, administratieve handelingen, reisboeken, etc. Allemaal zaken die nu gedaan worden door "mensen met ervaring" Die ervaring zal door AI-systemen geleerd worden waarna ze in eerste instantie ons zullen helpen bij onze werkzaamheden, maar alras een deel van onze taken zullen overnemen.
Waarschijnlijk is het niet zo dat wij (=mensen) er helemaal uitgewerkt zullen worden. De eindverantwoordelijkheid zal nog wel bij mensen blijven liggen, maar helemaal zelfstandig zullen we waarschijnlijk niet blijven. Vergelijk het met de steeds beter werkende automatische piloten in vliegtuigen. Na 9/11 is de software zo aan gepast dat gedrag als dat van de kapers niet meer zou moeten kunnen. Mooi, iedereen juicht dat toe, maar het houdt in dat de piloot niet meer 100% autonoom kan acteren. Zo zal het waarschijnlijk ook met AI gaan.
Descriptive, Predictive and Prescriptive Analytics explained
Beschrijvende, Voorspellende en Voorschrijvende Analyses.
Dit is eigenlijk hetzelfde als hierboven: Assess, Predict and Advise.
- Descriptive Analytics, which use data aggregation and data mining to provide insight into the past and answer: “What has happened?”
- Predictive Analytics, which use statistical models and forecasts techniques to understand the future and answer: “What could happen?”
- Prescriptive Analytics, which use optimization and simulation algorithms to advice on possible outcomes and answer: “What should we do?”
Max Welling:
het NEDAP-praatje.
"Wat computers echt nog niet kunnen", zegt Welling, "is het zelf formuleren van vragen en hypothesen over de wereld en dan de acties plannen die nodig zijn om deze informatie te vergaren. Met andere woorden: het autonoom de wereld leren ontdekken en deze begrijpen."
verder lezen: http://fortune.com/ai-artificial-intelligence-deep-machine-learning/