

Om de twee jaar komt de grote spraaktechnologieconferentie InterSpeech naar Europa en dit jaar was Dresden in Duitsland aan de beurt. Een goede gelegenheid voor zowel traditionele academische onderzoekers als, in toenemende mate, de TST-ontwikkelaars van grote en kleinere bedrijven. Nederlandse bedrijven waaronder {tooltip}NOTaS{end-texte}Nederlandse Organisatie van Taal en Spraaktechnologie{end-tooltip}-deelnemers, waren goed aanwezig: {tooltip}Telecats{end-texte|w=500|mood=80|tipd=1000|offsety=10}![]() 1 Telecats Met ruim 400 klanten is Telecats een toonaangevende onderneming op het gebied van innovatieve klantcontactoplossingen met o.a. Spraakherkenning.{end-tooltip} (2x), SpeechLab, NovoLanguage en ReadSpeaker.
1 Telecats Met ruim 400 klanten is Telecats een toonaangevende onderneming op het gebied van innovatieve klantcontactoplossingen met o.a. Spraakherkenning.{end-tooltip} (2x), SpeechLab, NovoLanguage en ReadSpeaker.
Samen met nog 1000 anderen liepen wij gedurende 4 dagen van 9 uur ’s morgens tot 19:00 ’s avonds van Oral Session -> Poster -> Show&Tell -> KeyNote. En niet alleen overdag, want ook ’s avonds ging het netwerken, uitwisselen van ideeën en ordinair roddelen gewoon door. Met als resultaat dat ongeveer iedereen opgelucht ademhaalde toen het einde nabij was: doodvermoeiend maar bereninteressant.
Waar ging het over?
4 jaar geleden kwam de onderzoeksgroep van Microsoft in Firenze naar buiten met het gebruik van Deep Neural Networking (DNN) voor spraakherkenning.
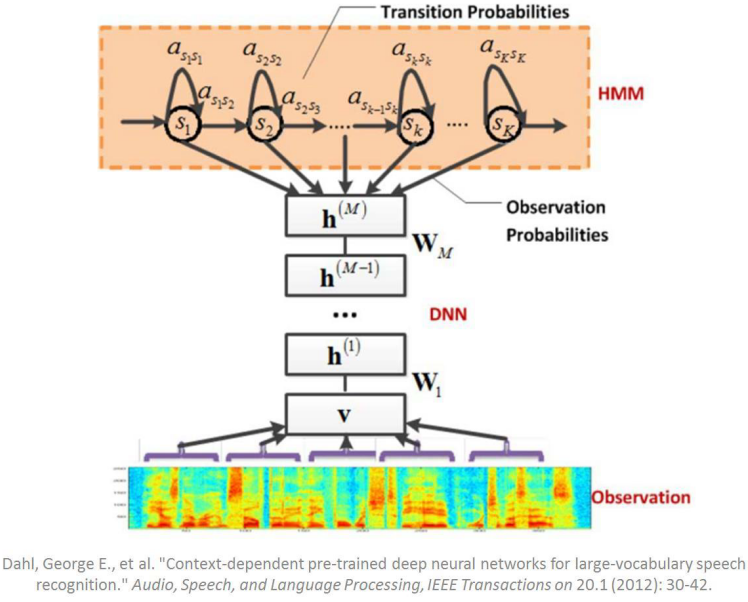 Een diep neuraal netwerk (DNN) is een kunstmatig neuraal netwerk met meerdere verborgen lagen tussen de ingang- en uitgangslaag. Een DNN genereert modellen waarbij de extra lagen het samenstellen features van onderliggende lagen mogelijk maken. Hierdoor wordt een enorm leervermogen gecreëerd die ingezet kan worden voor het modelleren van de complexe spraakpatronen. DNN’s zijn de meest populaire vormen van de “diep leren architectuur” en wordt sinds 2010 met veel succes gebruikt voor spraakherkenning sinds 2010. Een diep neuraal netwerk (DNN) is een kunstmatig neuraal netwerk met meerdere verborgen lagen tussen de ingang- en uitgangslaag. Een DNN genereert modellen waarbij de extra lagen het samenstellen features van onderliggende lagen mogelijk maken. Hierdoor wordt een enorm leervermogen gecreëerd die ingezet kan worden voor het modelleren van de complexe spraakpatronen. DNN’s zijn de meest populaire vormen van de “diep leren architectuur” en wordt sinds 2010 met veel succes gebruikt voor spraakherkenning sinds 2010. |
De resultaten in 2011 waren zo spectaculaire dat ongeveer de hele TST-onderzoekswereld zich vervolgens op dit fenomeen heeft geworpen: en dat is nog steeds te merken. Het leek er soms op dat ongeveer de helft van spraakherkenningspresentaties en posters op de een of andere manier over Deep-Deep-Deep Neural networking en allerlei nieuwe varianten ervan ging. En als zo’n DNN zoals bij mij, al op het randje van je kennis ligt, dan is ’n sessie van 2 uur met 6 DNN-presentaties beslist afzien. Nog erger wordt het wanneer een jonge Japanse of Chinese PhD-student het verhaal gaat vertellen. Hun Engels is voor ons (in ieder geval voor mij) soms moeilijk te volgen en dat in combinatie met de pittige wiskunde……..
Maar wel petje af voor deze onderzoekers, want sommigen leren het verhaal helemaal uit hun hoofd (wat dan wel weer lastig is als je hen na afloop iets wilt vragen). Ik moet er trouwens niet aan denken dat ik zoiets in het Chinees zou moeten doen.
Hoogtepunten
Wat waren in mijn ogen de hoogte punten van InterSpeech? De Show&Tellsessies (2 jaar geleden voor het eerst op InterSpeech) waren zeker de moeite waard (zie hieronder), maar de 3 hoogtepunten waren voor mij de 3 keynotes op dinsdag, woensdag en donderdag (die van maandag van Mary E. Beckman was een beetje warrig).
Keynotes
 Het verhaal van Ruhi Sarikaya (dinsdag) sprak mij het meest aan. Zijn basisgedachte is dat de spraakgestuurde assistenten zo goed gaan worden (of al zijn) dat ze de meeste apps van je mobiele telefoon gaan overnemen. Nu heb je gemiddeld nog 30 apps op je telefoon waarvan je er maar 4 a 5 echt gebruikt. Straks heb je eigenlijk alleen maar Cortana (SIRI, GoogleNow) en daarmee bedien je de apps op je telefoon.
Het verhaal van Ruhi Sarikaya (dinsdag) sprak mij het meest aan. Zijn basisgedachte is dat de spraakgestuurde assistenten zo goed gaan worden (of al zijn) dat ze de meeste apps van je mobiele telefoon gaan overnemen. Nu heb je gemiddeld nog 30 apps op je telefoon waarvan je er maar 4 a 5 echt gebruikt. Straks heb je eigenlijk alleen maar Cortana (SIRI, GoogleNow) en daarmee bedien je de apps op je telefoon.
En ik denk eigenlijk dat ie gelijk heeft. Voor de straight-forward opdrachten kun je net zo goed spraak gebruiken, zeker als je visuele feedback krijgt zodat je altijd ziet of het ok is. Het daadwerkelijke gebruik van visuele apps op je mobiel wordt dan teruggebracht tot het browsen en inspiratie opdoen. Een kleine test op mijn iPad liet zien dat dat nu al aardig gaat. “Hoe maak ik een lamsschotel” leidt tot een groot aantal recepten die ik vervolgens kan aanklikken. Maar het antwoord op de vraag “wat zal ik nu weer eens eten” is minder duidelijk: hier leent een visuele app met foto’s van smakelijke schotels zich beter voor.

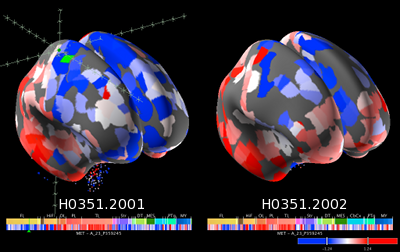 Ook de tweede keynote van Katrin Amunts op woensdag over de Human Brain Project Atlas was fascinerend. Zij houdt zich bezig met het maken van een atlas van onze hersenen. Dat gebeurt o.a. door hersenen van overleden mensen in heel dunne laagjes te snijden, die plakjes te fotograferen/scannen en met die scans en geavanceerde image-software een 3D-model van onze hersenen te maken. Fascinerend! Je kon met een muis gewoon door onze hersenen “lopen”.
Ook de tweede keynote van Katrin Amunts op woensdag over de Human Brain Project Atlas was fascinerend. Zij houdt zich bezig met het maken van een atlas van onze hersenen. Dat gebeurt o.a. door hersenen van overleden mensen in heel dunne laagjes te snijden, die plakjes te fotograferen/scannen en met die scans en geavanceerde image-software een 3D-model van onze hersenen te maken. Fascinerend! Je kon met een muis gewoon door onze hersenen “lopen”.
Door een MRI-scan van mensen te maken terwijl ze in de scanner naar “zinvolle of juist onzin spraak”, “muziek of kabaal”, “boze spraak of juist rustige spraak” luisteren krijg je te zien welke delen van de hersen betrokken zijn bij het processen van deze geluiden (uiteraard kun je dat ook met beelden of bewegingen (“til je linker hand op”) doen). Door dit te combineren met het 3D-model van de hersenen wordt duidelijk waar in de hersenen wat geprocessed wordt. Dat leidt tot betere inzicht, maakt duidelijk waar je af moet blijven bij operaties en geeft aan hoe onze hersenen spraak en beeld verwerken hetgeen dan weer door onderzoekers gebruikt kan worden om nog betere beeld en spraakprocessing te maken.
 De laatste keynote op donderdag door Klaus Scherer ging over de evolutionaire ontwikkeling van spraak. Hoe zijn wij van een klanken uitstotende veredelde aap tot sprekende mensen geworden? Aan de hand van allerlei voorbeelden van geluidmakende dieren (antilopen, verschillende soorten apen) liet hij zien hoe die ontwikkeling mogelijkerwijs verlopen is. Zo kunnen apen bij een “alarmmelding” aangeven of het een roofvogel, een leeuw of een slang is waarvoor opgepast moet worden.
De laatste keynote op donderdag door Klaus Scherer ging over de evolutionaire ontwikkeling van spraak. Hoe zijn wij van een klanken uitstotende veredelde aap tot sprekende mensen geworden? Aan de hand van allerlei voorbeelden van geluidmakende dieren (antilopen, verschillende soorten apen) liet hij zien hoe die ontwikkeling mogelijkerwijs verlopen is. Zo kunnen apen bij een “alarmmelding” aangeven of het een roofvogel, een leeuw of een slang is waarvoor opgepast moet worden.

Wat viel op?
Wat verder erg leuk was, waren de Show&Tell sessies. De moderne tijd is ook bij InterSpeech doorgedrongen en naast de traditionele postersessies zijn er nu sessies die ergens tussen een statische verhaal op papier en een demonstratie op de computer in liggen. Zo liet men zien dat de spraakherkenning behoorlijk goed werkt bij het annoteren van vergaderingen (Intel), dat je heel snel via een Virtual Machine een eigen spraakherkenner kunt opzetten zodat je bijvoorbeeld tijdens een werkcollege de studenten met echte ASR kunt laten werken (SpeechLitchen), en dat je een systeem kunt maken dat sprekers herkent die al eerder een 112-noodnummer hebben gebeld (“Hallo, u belde net ook al!”).
Kortom, de Show&Tell sessies zijn volgens mij de manier om de resultaten van TST-onderzoek te presenteren. Het is toch eigenlijk vreemd dat we nog steeds een groot vel met dikwijls kleine lettertjes en plaatjes aan de muur hangen en dan gaan uitleggen wat we allemaal gedaan hebben als je het ook gewoon kunt laten zien en horen. Enige reden die ik nu kan bedenken dat het nog niet op grote schaal gedaan wordt, zijn de kosten: papier is goedkoop en het inrichten van een zaal met 60 grote monitors kost nu nog te veel. Bij de volgende NOTaS-show maar eens proberen?
Het publiek
 De bezoekers van InterSpeech hebben traditioneel een hoog nerd gehalte. De merendeels mannelijke deelnemers bekommeren zich in de regel niet echt om uiterlijk vertoon al doet een aantal “paradijsvogels” soms anders vermoeden. Een aantal Nederlandse nieuwkomers vroeg de avond voor de conferentie nog of er een dresscode was: ze hadden tenslotte een jasje en zo meegenomen. Mwah, verspilde moeite. Loop rond waar je je prettig in voelt en stel vooral slimme vragen. Dat eerste was eenvoudig, dat tweede iets lastiger omdat je diep van binnen toch bang bent een hele stomme vraag te stellen tussen al dit mathematische geweld.
De bezoekers van InterSpeech hebben traditioneel een hoog nerd gehalte. De merendeels mannelijke deelnemers bekommeren zich in de regel niet echt om uiterlijk vertoon al doet een aantal “paradijsvogels” soms anders vermoeden. Een aantal Nederlandse nieuwkomers vroeg de avond voor de conferentie nog of er een dresscode was: ze hadden tenslotte een jasje en zo meegenomen. Mwah, verspilde moeite. Loop rond waar je je prettig in voelt en stel vooral slimme vragen. Dat eerste was eenvoudig, dat tweede iets lastiger omdat je diep van binnen toch bang bent een hele stomme vraag te stellen tussen al dit mathematische geweld.
Conclusie
 InterSpeech laat zien dat TST zich langzaam losmaakt van “alleen maar onderzoek”. Doordat met name de spraakherkenning zo goed geworden is, dat je het echt kunt gebruiken, wordt de technologie voor allerlei bedrijven bruikbaar. Dat verklaart waarschijnlijk ook het grote aantal medewerkers van IBM, Apple (30!), Microsoft, Google, Amazon, FaceBook en NOTaS J. De eerste horde, het daadwerkelijk herkennen van wat er gezegd wordt, lijkt in ieder geval voor de grote talen (Engels, Chinees, Japans, Spaans, Duits, Frans en Italiaans) genomen waardoor men zich nu kan richten op het interpreteren van de spraak (Speech Understanding). Ook hiervoor was erg veel belangstelling en het is te verwachten dat tijdens InterSpeech2016 (San Francisco) en InterSpeech2017 (Stockholm) er enorm veel toepassingsgerichte ontwikkelingen zullen zijn.
InterSpeech laat zien dat TST zich langzaam losmaakt van “alleen maar onderzoek”. Doordat met name de spraakherkenning zo goed geworden is, dat je het echt kunt gebruiken, wordt de technologie voor allerlei bedrijven bruikbaar. Dat verklaart waarschijnlijk ook het grote aantal medewerkers van IBM, Apple (30!), Microsoft, Google, Amazon, FaceBook en NOTaS J. De eerste horde, het daadwerkelijk herkennen van wat er gezegd wordt, lijkt in ieder geval voor de grote talen (Engels, Chinees, Japans, Spaans, Duits, Frans en Italiaans) genomen waardoor men zich nu kan richten op het interpreteren van de spraak (Speech Understanding). Ook hiervoor was erg veel belangstelling en het is te verwachten dat tijdens InterSpeech2016 (San Francisco) en InterSpeech2017 (Stockholm) er enorm veel toepassingsgerichte ontwikkelingen zullen zijn.
Voor NOTaS een goede ontwikkeling!