
Met een kleine woordenschat, spreek je al een aardig mondje mee!
Laatst kreeg ik mijn dagelijkse nieuwsbrief “De Bicker” in de mail met daarin een enthousiasmerend stuk over de “Wet van Zipf” en het "Pareto-principe" (u weet wel van die 80-20 regel) en een link naar een 21-minuten durend geweldig boeiende en humoristische filmpje waarin het wordt uitgelegd en aannemelijk wordt gemaakt waarom het zo is.
En dan niet alleen voor het vóórkomen van woorden maar ook voor andere zaken zoals populariteit, sneeuwballen en rijkdom. Deze door George Kingsley Zipf gevonde wetmatigheid wordt ook wel de "Wet van Zipf" genoemd.
De krant lezen in een jou redelijk onbekende taal
 Het zal de meeste mensen wel zijn opgevallen dat, ergens op vakantie in een land waarvan je de taal niet goed spreekt, je met enige oefening en een beetje geduld al snel de krant zo kunt lezen dat je in ieder geval begrijpt waarover men zich die dag druk maakt.
Het zal de meeste mensen wel zijn opgevallen dat, ergens op vakantie in een land waarvan je de taal niet goed spreekt, je met enige oefening en een beetje geduld al snel de krant zo kunt lezen dat je in ieder geval begrijpt waarover men zich die dag druk maakt.
Maar komt dat nu omdat ik zo slim ben of schrijven die buitenlandse kranten voor heeeel eenvoudige mensen?
Dat laatste kan natuurlijk waar zijn (net als het eerste :-)) maar het ligt waarschijnlijk net iets anders.
Experimentje: verdeling woorden in de taal
De verdeling van de woorden in een taal (hoe vaak wordt elk woord gebruikt) volgt een soort wetmatigheid. Het meest voorkomende woord (in het het Nederlands is dat "de") komt heel veel voor.
Om te zien of het allemaal klopt, heb ik een lang artikel uit de Correspondent genomen (50 min leestijd, 2690 unieke woorden en 12775 woorden totaal). De berekening van de woordfrequenties geeft het volgende resultaat.
Als we de tabel met de meest gebruikte woorden bekijken, dan zien we dat de 5 populairste die samen al meer dan 18% van het totaal aantal woorden vormen. In de grafiek zien we dat als we de helft van de woorden willen “kennen”, we slechts 75 woorden hoeven te leren. Als we naar 80% willen gaan, dan volstaan "slechts" 642 woorden.
Dus met een beetje oefenen kent zo’n artikel bijna geen geheimen meer.
| rangorde | woord | aantal | % | gesommeerd % |
| 1 | de | 914 | 7,155% | 7,155% |
| 2 | van | 482 | 3,773% | 10,928% |
| 3 | het | 381 | 2,982% | 13,910% |
| 4 | in | 312 | 2,442% | 16,352% |
| 5 | een | 289 | 2,262% | 18,614% |
| ... | ||||
| 75 | had | 26 | 0,204% | 50,137% |
| ... | ||||
| 642 | draadloos | 3 | 0,023% | 80,016% |

Woordfrequentie van een krantenartikel uit de Correspondent. 12775 woorden waarvan 2690 uniek.
Spreken & Schrijven
Maar, hoe zit dat met de spraaktaal? De wetmatigheid blijft maar de rangorde verandert een beetje. Voor gesproken taal kan er gekeken worden naar het Corpus Gesproken Nederlands (CGN) waarin zo'n 900 uur spreektaal is opgenomen en elk woord werd uitgeschreven. Voor geschreven taal is er het PAROLE-corpus: een verzameling van zo'n 20 miljoen woorden uit boeken, kranten en tijdschriften, uit de periode 1982-1998.
| CGN | ja | dat | de | en | uh | ik | een | is | die | van |
| PAROLE | dat | van | het | een | en | in | is | te | dat | op |
Voor en Achternamen
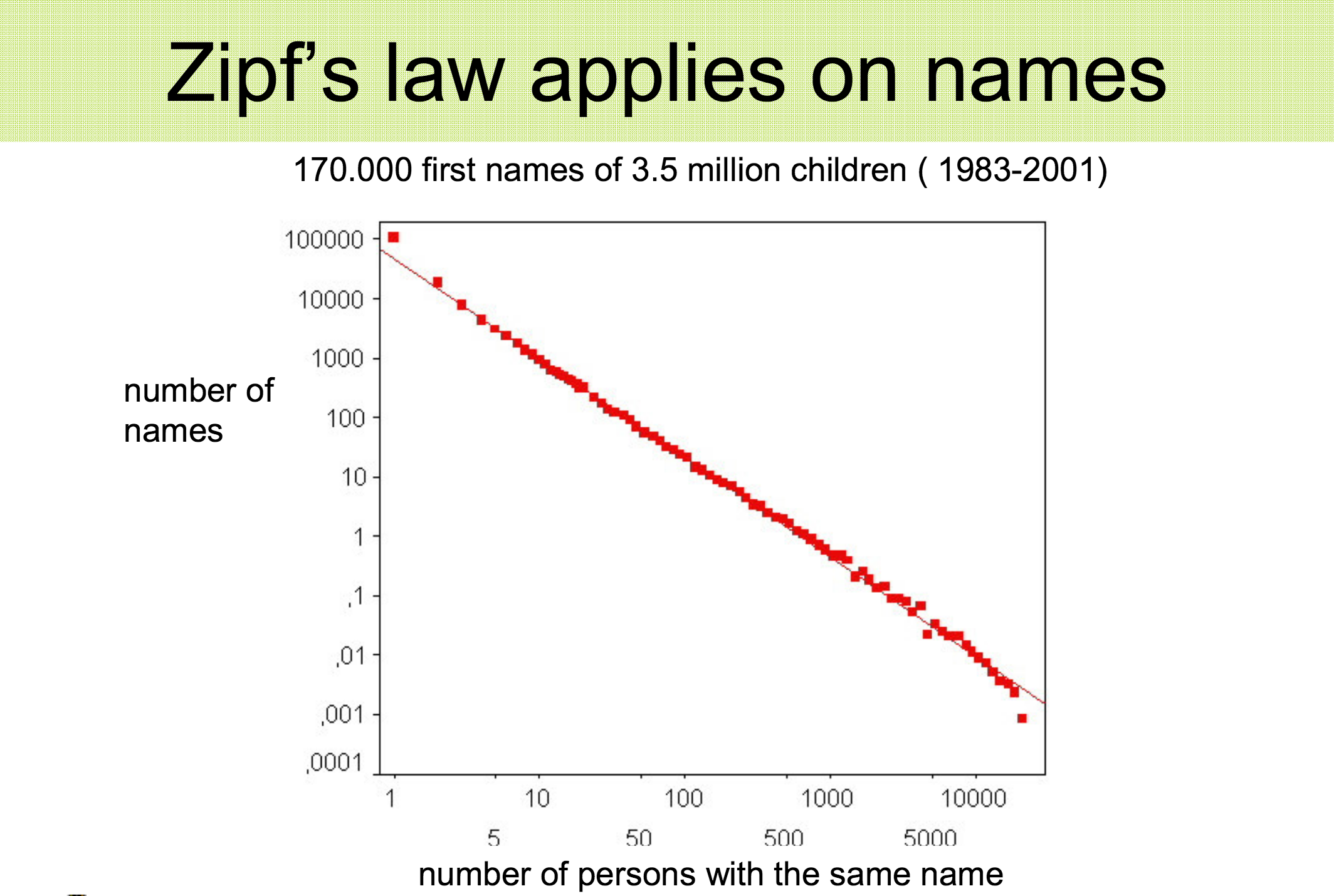
Gerrit Bloothooft (UU, Meerten Instituut) heeft in een boeiend artikel laten zien dat de Wet van Zipf ook geldt voor het voorkomen van voor- en achternamen. Door het aantal en de frequentie op een dubbel-logarithmische schaal te plotten, krijg je een keurig rechte lijn: een Zipf-verdeling.
Conclusie
Als we de sommatie van de zipf-verdeling nemen, dan zien we direct dat je met kennis van een paar honderd veel voorkomende woorden al heel veel teksten kunt lezen. Natuurlijk zullen er in die tekst ook weinig voorkomende en wellicht belangrijke woorden staan die ervoor zorgen dat je net niet begrijpt wat er precies staat. Maar de algemene betekenis haal je meestal wel uit de context. Het verklaart in ieder geval wel waarom je, met slechts een geringe woordenschat, toch die krant of dat boek kunt lezen. En de "Wet van Zipf" geldt voor veel meer zaken, zoals in het filmpje wordt duidelijk gemaakt.